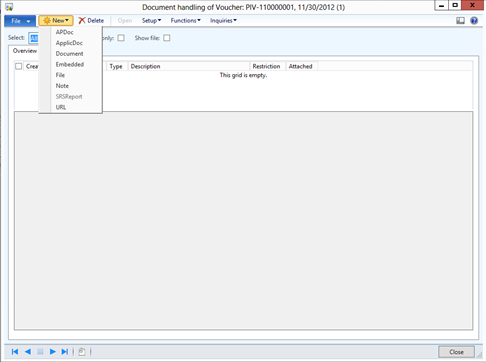
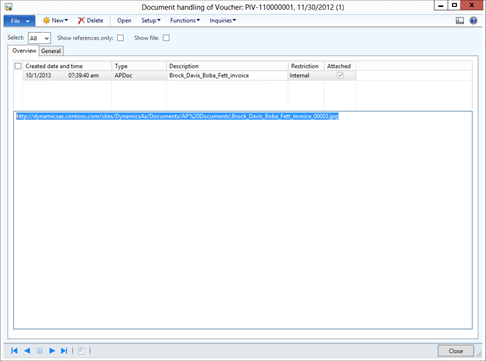
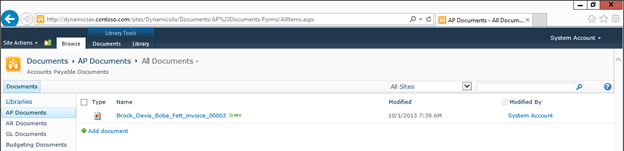
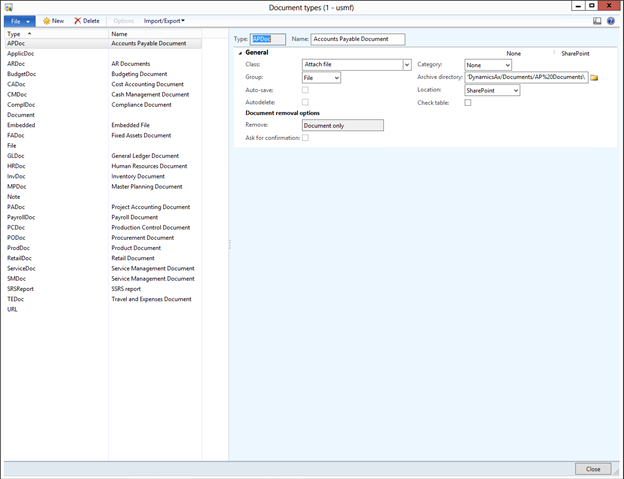
Features
- Manageable Routing Service
- Mapping physical to logical endpoints
- Managing routing messages from Repository
- No Service interruptions
- Adding more outbound endpoints on the fly
- Changing routing rules on the fly
- .Net 4 Technologies
Introduction
Recently released Microsoft .Net 4 Technology represents a foundation technology for metadata driven model applications. This article focuses on one of the unique components from the WCF 4 model for logical connectivity such as a Routing Service. I will demonstrate how we can extend its usage for enterprise application driven by metadata stored in the Runtime Repository. For more details about the concept, strategy and implementation of the metadata driven applications, please visit my previous articles such as Contract Model and Manageable Services.
I will highlight the main features of the Routing Service, more details can be found in the following links [1], [2], [3].
From the architectural style, the Router represents a logical connection between the inbound and outbound endpoints. This is a “short wire” virtual connection in the same appDomain space described by metadata stored in the router table. Based on these rules, the messages are exchanged via the router in the specific built-in router pattern. For instance, the WCF Routing Service allows the following Message Exchange Pattern (MEP) with contract options:
- OneWay (SessionMode.Required, SessionMode.Allowed, TrasactionFlowOption.Allowed)
- Duplex (OneWay, SessionMode.Required, CallbackContract, TrasactionFlowOption.Allowed)
- RequestResponse (SessionMode.Allowed, TrasactionFlowOption.Allowed)
In addition to the standard MEPs, the Routing Service has a built-in pattern for Multicast messaging and Error handling.

The router process is very straightforward, where the untyped message received by inbound endpoint is forwarding to the outbound endpoint or multiple endpoints based on the prioritized rules represented by message filter types. The evaluation rules are started by highest priority. The router complexity is depended by number of inbound and outbound endpoints, type of message filters, MEPs and priorities.
Note, that the MEP pattern between the routed inbound and outbound endpoints must be the same, for example: the OneWay message can be routed only to the OneWay endpoint, therefore for routing Request/Response message to the OneWay endpoint, the service mediator must be invoked to change the MEP and then back to the router.
A routing service enables an application to physically decouple a process into the business oriented services and then logical connected (tight) in the centralized repository using a declaratively programming. From the architecture point of view, we can consider a routing service as a central integration point (hub) for private and public communication.
The following picture shows this architecture:

As we can see in the above picture, a centralized place of the connectivity represented by Routing Table. The Routing Table is the key component of the Routing service, where all connectivity is declaratively described. These metadata are projected on runtime for message flowing between the inbound to outbound points. Messages are routing between the endpoints in the full transparent manner. The above picture shows the service integration with the MSMQ Technology via routing. The queues can be plugged-in to the Routing Table integration part like another service.
From the metadata driven model point of view, the Routing Table metadata are part of the logical business model, centralized in the Repository. The following picture shows an abstraction of the Routing Service to the Composite Application:

The virtualization of the connectivity allows encapsulating a composite application from the physical connectivity. This is a great advantage for model driven architecture, where internally, all connectivity can be used well know contracts. Note, that the private channels (see the above picture – logical connectivity) are between the well know endpoints such as Routing Service and Composite Application.
Decoupling sources (consumers) from the target endpoints and their logical connection driven by metadata will enable our application integration process for additional features such as:
- Mapping physical to logical endpoints
- Virtualization connectivity
- Centralized entry point
- Error handling with alternative endpoints
- Service versioning
- Message versioning
- Service aggregation
- Business encapsulation
- Message filtering based on priority routing
- Metadata driven model
- Protocol bridging
- Transacted message routing
As I mentioned earlier, in the model driven architecture, the Routing Table is a part of the metadata stored in the Repository as a Logical Centralized Model. The model is created by design time and then physical decentralized to the target. Note, deploying model for its runtime projecting will require recycling the host process. To minimize this interruption, the Routing Service can help to isolate this glitch by managing the Routing Table dynamically.
The WCF Routing Service has built-in a feature for updating a Routing Table at the runtime. The default bootstrap of the routing service is loading the table from the config file (routing section). We need to plug-in a custom service for updating the routing table in the runtime. That’s the job for Routing Manager component, see the following picture:

Routing Manager is a custom WCF Service responsible for refreshing the Table located in the Routing Service from the config file or Repository. The first inbound message (after the host process is opened) will boot the Table from the Repository automatically. During the runtime time, when the routing service is active, the Routing Manager must receive an inquiry message to load a routing metadata from the Repository and then update the Table.
Basically, the Routing Manager enables our virtualized composite application to manage this integration process without recycling a host process. There is one conceptual architectural change in this model. As we know, the Repository pushed (deployed) metadata for its runtime projecting to the host environment (for instance: IIS, WAS, etc.). This runtime metadata is stored in the local, private repository such as file system and it is used for booting our application, services.
That’s a standard Push phase such as Model->Repository->Deploy. The Routing Service is a good candidate for introducing a concept of the Pull phase such as Runtime->Repository, where the model created during the design time can be changed during its processing in the transparent manner. Therefore, we can decide about the runtime metadata used by Pull model during the design time as well.
Isolating metadata for boot projector and runtime update enables our Repository to administrate application without interruptions, for instance, we can change physical endpoint, binding, plug-in a new service version, new contract, etc. Of course, we can build more sophisticated tuning system, where runtime metadata can be created and/or modified by analyzer, etc. In this case, we have a full control loop between the Repository and Runtime.
Finally, the following picture is an example of the manageable routing service:

As the above picture shows, the manageable Routing Service represents central virtualizations of the connectivity between workflow services, services, queues and web services. The Runtime Repository represents a routing metadata for booting process and also runtime changes. The routing behavior can be changed on the fly in the common shareable database (Repository) and then it can be synchronized with runtime model by Routing Manager.
One more “hidden” feature of the Routing Service can be seen in the above picture, such as scalability. Decomposition of the application into the small business oriented services and composition via a routing service; we can control scalability of the application. We can assign localhost or cluster address of the logical endpoints based on the routing rules.
From the virtualization point of the view, the following picture shows a manageable composite application:

As you can see, the Composite Application is driven by logical endpoints, therefore can be declared within the logical model without the physical knowledge where they are located. Only the Runtime Repository knows these locations and can be easily managed based on requirements, for example: dev, staging, QA, production, etc.
This article is focusing on the Routing Manager hosted on IIS/WAS. I am assuming you have some working experience or understand features of the WCF4 Routing Service.
OK, let’s get started with Concept and Design of the Manageable Routing Service.
Concept and Design
The concept and design of the Routing Manager hosted on IIS/WAS is based on the extension of the WCF4 Routing Service for additional features such as downloading metadata from Repository in the loosely coupled manner. The plumbing part is implemented as a common extension to services (RoutingService and RoutingManager) named as routingManager. Adding the routingManager behavior to the routing behavior (see the following code snippet), we can boot a routing service from the repositoryEndpointName.

The routingManager behavior has the same attributes like routing one with additional attribute for declaration of the repository endpoint. As you can see, it is very straightforward configuration for startup routing service. Note, that the routingManager behavior is a pair to the routing behavior.
Now, in the case of updating routing behavior on the runtime, we need to plug-in a Routing Manager service and its service behavior routingManager. The following code snippet shows an example of activations without the .svc file within the same application:

and its service behavior:

Note, that the repositoryEndpointName can be addressed to different Repository than we have at the process startup.
Routing Manager Contract
Routing Manager Contract allows to communicate with Routing Manager service out of the appDomain. The Contract Operations are designed for broadcasting and point to point patterns. Operation can be specified for specific target or for unknown target (*) based on the machine and application names. The following code snippet shows the IRoutingManager contract:
 Collapse
Collapse |
Copy Code[ServiceContract(Namespace = "urn:rkiss/2010/09/ms/core/routing",
SessionMode = SessionMode.Allowed)]
public interface IRoutingManager
{
[OperationContract(IsOneWay = true)]
void Refresh(string machineName, string applicationName);
[OperationContract]
void Set(string machineName, string applicationName, RoutingMetadata metadata);
[OperationContract]
void Reset(string machineName, string applicationName);
[OperationContract]
string GetStatus(string machineName, string applicationName);
}
The Refresh operation represents an inquiry event for refreshing a routing table from the Repository. Based on this event, the Routing Manager is going to pick-up a “fresh” routing metadata from the Repository (addressed by repositoryEndpointName) and update the routing table.
Routing Metadata Contract
This is a Data contract between the Routing Manager and Repository. I decided to use it for the contract routing configuration section as xml formatted text. This selection gives me an integration and implementation simplicity and easy future migration. The following code snippet is an example of the routing section:

and the following is Data Contract for repository:
Collapse |
Copy Code
[DataContract(Namespace = "urn:rkiss/2010/09/ms/core/routing")]
public class RoutingMetadata
{
[DataMember]
public string Config { get; set; }
[DataMember]
public bool RouteOnHeadersOnly { get; set; }
[DataMember]
public bool SoapProcessingEnabled { get; set; }
[DataMember]
public string TableName { get; set; }
[DataMember]
public string Version { get; set; }
}
OK, that should be all from the concept and design point on the view, except one thing what was necessary to figure out, especially for hosting services on the IIS/WAS. As we know [1], there is a RoutingExtension class in the System.ServiceModel.Routing namespace with a “horse” method ApplyConfiguration for updating routing service internal tables.
I used the following “small trick” to access this RoutingExtension from another service such as RoutingManager hosted by its own factory.
The first routing message will stored the reference of the RoutingExtension into the AppDomain Data Slot under the well-known name, such as value of the CurrentVirtualPath.
Collapse |
Copy Code
serviceHostBase.Opened += delegate(object sender, EventArgs e)
{
ServiceHostBase host = sender as ServiceHostBase;
RoutingExtension re = host.Extensions.Find<RoutingExtension>();
if (configuration != null && re != null)
{
re.ApplyConfiguration(configuration);
lock (AppDomain.CurrentDomain.FriendlyName)
{
AppDomain.CurrentDomain.SetData(this.RouterKey, re);
}
}
};
Note, that both services such as RoutingService and RoutingManager are hosted under the same virtual path, therefore the RoutingManager can get this Data Slot value and cast it to the RoutingExtension. The following code snippet shows this fragment:
Collapse |
Copy Code
private RoutingExtension GetRouter(RoutingManagerBehavior manager)
{
lock (AppDomain.CurrentDomain.FriendlyName)
{
return AppDomain.CurrentDomain.GetData(manager.RouterKey) as RoutingExtension;
}
}
Ok, now it is the time to show the usage of the Routing Manager.
Usage and Test
The Manageable Router (RoutingService + RoutingManager) features and usage, hosted on the IIS/WAS, can be demonstrated via the following test solution. The solution consists of the Router and simulators for Client, Services and LocalRepository.

The primary focus is on the Router, as shown in the above picture. As you can see, there are no .svc files, etc., just configuration file only. That’s right. All tasks to setup and configure manageable Router are based on the metadata stored in the web.config and Repository (see later discussion).
The Router project has been created as an empty web project under http://localhost/Router/ virtualpath, adding an assembly reference from RoutingManager project and declaring the following sections in the web.config.
Let’s describe these sections in more details.
Part 1. – Activations
These sections are mandatory for any Router such as activation of the RoutingService and RoutingManager service, behavior extension for routingManager and declaring client endpoint for Repository connectivity. The following picture shows these sections:

Note, this part also declares relative address for our Router. In the above example, the entry point for routing message is ~/Pilot.svc and access to RoutingManager has address ~/PilotManager.svc.
Part 2. – Service Endpoints
In these sections, we have to declare endpoints for two services such as RoutingService and RoutingManager. The RoutingService endpoints have untyped contracts defined in the System.ServiceModel.Routing namespace. In this test solution, we are using two contracts, one for notification (OneWay) and the other one is for RequestReply message exchange. The binding is used by basicHttpBinding, but it can be any standard or custom binding based on the requirements.
The RoutingManager service is configured with simple basicHttpBinding endpoint, but in the production version, it should use a custom udp channel for broadcasting message to trigger the pull metadata process from the Repository across the cluster.

Part 3. – Plumbing RoutingService and Manager together
This section will attach a RoutingService to the RoutingManager for accessing its RoutingExtension in the runtime.

The first extBehavior section is a configuration of the routing boot process. The second one is a section for downloading routing metadata during the runtime.
OK, that’s all for creating a manageable Router.
The following picture shows a full picture of the solution:

As you can see, there is the Manageable Router (hosted in the IIS/WAS) for integration of the composite application. On the left hand side is the Client simulator to generate two operations (Notify and Echo) to the Service1 and/or Service2 based on the routing rules. The Client and Services are regular WCF self-hosted applications, the client can talk directly to the Services or via the Router.
Local Repository
Local Repository represents a metadata storage of the metadata such as logical centralized application model, deployment model, runtime model, etc. Models are created during the design time and based on the deployment model are pushed (physical decentralized) to the targets where they are projecting on the runtime. For example: The RouterManager assembly and web.config are metadata for deploying model from the Repository to the IIS/WAS Target.
During the runtime, some components have capability to update behavior based on the new metadata pulled from the Repository. For example, this component is a manageable Router (RouterService + RouterManager). Building Enterprise Repository and Tools is not a simple task, see more details about Microsoft strategy here [6] and interesting example here [7], [8].
In this article, I included very simple Local Repository for Routing metadata with self-hosting service to demonstrate a capability of the RoutingManager Service. The Routing metadata is described by system.serviceModel section. The following picture shows a configuration root section for remote routing metadata:

As you can see, the content of the system.ServiceModel section is similar to the target web.config. Note, that the Repository is holding these sections only. They are related to the Routing metadata. By selecting RoutingTable tab, the routing rules will be displayed in the table form:

Any changes in the Routing Table will update a local routing metadata by pressing the button Finnish, but runtime Router must be notified about this change by pressing button Refresh. In this scenario, the LocalRepository will send an inquiry message to the RoutingManager for pulling a new routing metadata. You can see this action in the Status tab.
Routing Rules
The above picture shows a Routing Table as a representation of the Routing Rules mapped to the routing section in the configuration metadata. This test solution has a pre-build routing ruleset with four rules. Let’s describes these rules. Note, we are using an XPath filter for message body, therefore the option RouteOnHeadersOnly must be unchecked. Otherwise the Router will throw an exception.
The Router is deployed with two inbound endpoints such as SimplexDatagram and RequestReply, therefore the received message will be routed based on the following rules:
Request/Reply rules
First, as the highest priority (level 3) the message is buffered for xpath body expression
Collapse |
Copy Code
starts-with(/s11:Envelope/s11:Body/rk:Echo/rk:topic, 2)
if the xpath expression is true, then the copied message is routing to the outbound endpoint TE_Service1, else the copied message is forwarded to the TE_Service2 (see the filter aa)
SimplexDatagram rules
This is a multicast routing (same priority 2) to the two outbound endpoints such as TE_Service1 and TE_Service2. If the message cannot be delivered to the TE_Service2, the alternative endpoint from the backup list is used, such as Test1 (queue). Note, that the message is not buffered, it is passed directly (filterType = EndpointName) from endpointNotify endpoint.
Test
Testing Router is a very simple process. Launch the Client, Service1, Service2 and Local Repository programs, create VirtualDirectory in IIS/WAS for http://localhost/Router project and the solution is ready for testing. The following are instruction steps:
- On the Client form, press button Echo. You should see a message routed to the Service2
- Press button Echo again, the message is routed to the Service1
- Press button Echo again, the message is routed to the Service2
- Change Router combo box to:
http://localhost/Router/Pilot.svc/Notify
- Press button Event, see notification messages in both services
You can play with Local Repository to change the routing rules to see how the Router will handle the delivery messages.
For testing a backup rule, create a transactional queue Test1 and close the Service2 console program and follow the Step 2. and 3. You should see messages in the Service1 and queue.
Troubleshooting
There are two kinds of troubleshooting in the manageable Router. The first one is a built-in standard WCF tracing log and its viewing by Microsoft Service Trace Viewer program. The Router web.config file has already specified this section for diagnostics, but it is commented.
The second way to troubleshoot router with focus on the message flowing is built-in custom message trace inspector. This inspector is injected automatically by RoutingManager and its service behavior. We can use DebugView utility program from Windows Sysinternals to view the trace outputs from the Router.
Some Router Tips
1. Centralizing physical outbound connections into one Router enables the usage of logical connections (alias addresses) for multiple applications. The following picture shows this schema:

Instead of using physical outbound endpoints for each application router, we can create one master Router for virtualization of all public outbound endpoints. In this scenario, we need to manage only the master router for each physical outbound connection. The same strategy can be used for physical inbound endpoints. Another advantage of this router hierarchy is centralizing pre-processing and post-processing services.
2. As I mentioned earlier, the Router enables decomposition of the business workflow into small business oriented services, for instance: managers, workers, etc. The composition of the business workflow is declared by Routing Table which represents some kind of dispatcher of the messages to the correct service. We should use ws binding with a custom headers to simplify dispatching messages via a router based on the headers only.
Implementation
Based on the concept and design, there are two pieces for implementation, such as RoutingManager service and its extension behavior. Both modules are using the same custom config library, where useful static methods are located for getting clr types from the metadata stored in the xml formatted resource. I used this library in my previous articles (.Net 3) and I extended it for the new routing section.
In the following code snippet I will show you how straightforward implementation is done.
The following code snippet is a demonstration of the Refresh implementation for RoutingManager Service. We need to get some configurable properties from the routingManager behavior and access to the RouterExtension. Once we have them, the RepositoryProxy.GetRouting method is invoked to obtain routing metadata from the Repository.
We get the configuration section in the xml formatted text like from the application config file. Now, using the “horse” config library, we can deserialize a text resource into the clr object, such as MessageFilterTable<IEnumerable<ServiceEndpoint>>.
Then the RoutingConfiguration instance is created and passed to the router.ApplyConfiguration process. The rest of the magic is done in the RoutingService.
Collapse |
Copy Code
public void Refresh(string machineName, string applicationName)
{
RoutingConfiguration rc = null;
RoutingManagerBehavior manager =
OperationContext.Current.Host.Description.Behaviors.Find<RoutingManagerBehavior>();
RoutingExtension router = this.GetRouter(machineName, applicationName, manager);
try
{
if (router != null)
{
RoutingMetadata metadata =
RepositoryProxy.GetRouting(manager.RepositoryEndpointName,
Environment.MachineName, manager.RouterKey, manager.FilterTableName);
string tn = metadata.TableName == null ?
manager.FilterTableName : metadata.TableName;
var ft = ServiceModelConfigHelper.CreateFilterTable(metadata.Config, tn);
rc = new RoutingConfiguration(ft, metadata.RouteOnHeadersOnly);
rc.SoapProcessingEnabled = metadata.SoapProcessingEnabled;
router.ApplyConfiguration(rc);
foreach (var filter in rc.FilterTable)
{
foreach (var se in filter.Value as IEnumerable<ServiceEndpoint>)
{
if (se.Behaviors.Find<TraceMessageEndpointBehavior>() == null)
se.Behaviors.Add(new TraceMessageEndpointBehavior());
}
}
}
}
catch (Exception ex)
{
RepositoryProxy.Event( ...);
}
}
The last action in the above Refresh method is injecting the TraceMessageEndpointBehavior for troubleshooting messages within the RoutingService on the Trace output device.
The next code snippets show some details from the ConfigHelper library:
Collapse |
Copy Code
public static MessageFilterTable<IEnumerable<ServiceEndpoint>>CreateFilterTable(string config, string tableName)
{
var model = ConfigHelper.DeserializeSection<ServiceModelSection>(config);
if (model == null || model.Routing == null || model.Client == null)
throw new Exception("Failed for validation ...");
return CreateFilterTable(model, tableName);
}
The following code snippet shows a generic method for deserializing a specific type section from the config xml formatted text:
Collapse |
Copy Code
public static T DeserializeSection<T>(string config) where T : class
{
T cfgSection = Activator.CreateInstance<T>();
byte[] buffer =
new ASCIIEncoding().GetBytes(config.TrimStart(new char[]{'\r','\n',' '}));
XmlReaderSettings xmlReaderSettings = new XmlReaderSettings();
xmlReaderSettings.ConformanceLevel = ConformanceLevel.Fragment;
using (MemoryStream ms = new MemoryStream(buffer))
{
using (XmlReader reader = XmlReader.Create(ms, xmlReaderSettings))
{
try
{
Type cfgType = typeof(ConfigurationSection);
MethodInfo mi = cfgType.GetMethod("DeserializeSection",
BindingFlags.Instance | BindingFlags.NonPublic);
mi.Invoke(cfgSection, new object[] { reader });
}
catch (Exception ex)
{
throw new Exception("....");
}
}
}
return cfgSection;
}
Note, the above static method is a very powerful and useful method for getting any type of config section from the xml formatted text resource, which allows us using the metadata stored in the database instead of the file system – application config file.
Conclusion
In conclusion, this article described a manageable Router based on the WCF4 Routing Service. Manageable Router is allowing dynamically change routing rules from the centralized logical model stored in the Repository. The Router represents a virtualization component for mapping logical endpoints to the physical ones and it is a fundamental component in the model driven distributed architecture.
References:
[1] http://msdn.microsoft.com/en-us/library/ee517421(v=VS.100).aspx
[2] http://blogs.msdn.com/routingrules/archive/2010/02/09/routing-service-features-dynamic-reconfiguration.aspx
[3] http://weblogs.thinktecture.com/cweyer/2009/05/whats-new-in-wcf4-routing-service—or-look-ma-just-one-service-to-talk-to.html
[4] http://dannycohen.info/2010/03/02/wcf-4-routing-service-multicast-sample/
[5] http://blogs.profitbase.com/tsenn/?p=23
[6] SQL Server Modeling CTP and Model-Driven Applications
[7] Model Driven Content Based Routing using SQL Server Modeling CTP – Part I
[8] Model Driven Content Based Routing using SQL Server Modeling CTP – Part II
[9] Intermediate Routing
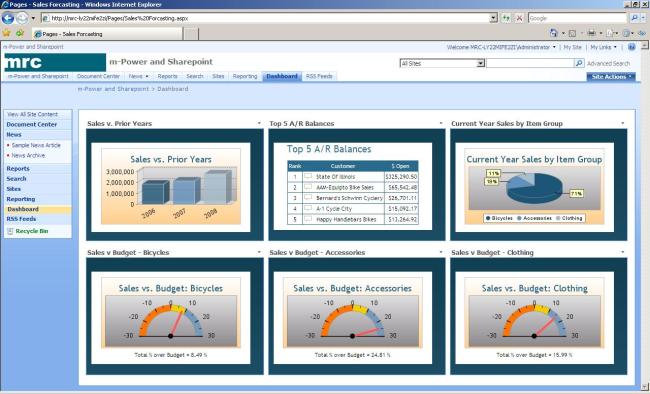
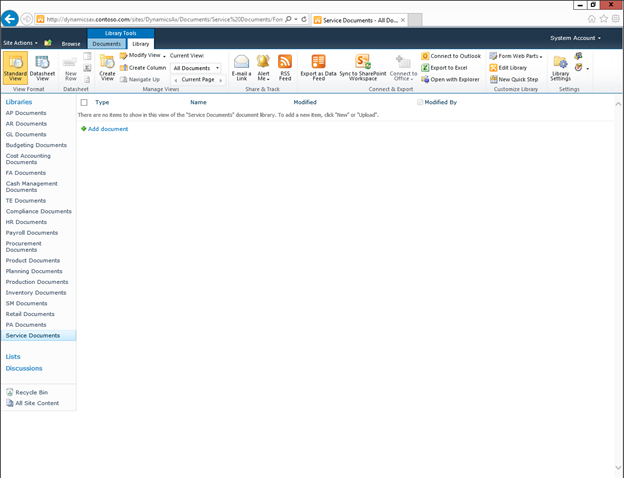
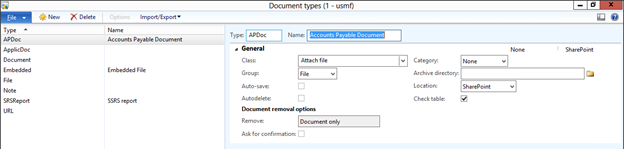
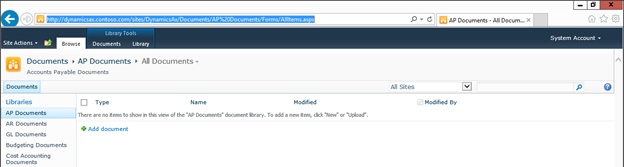
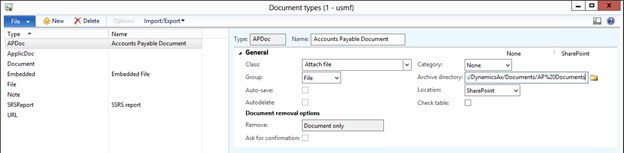
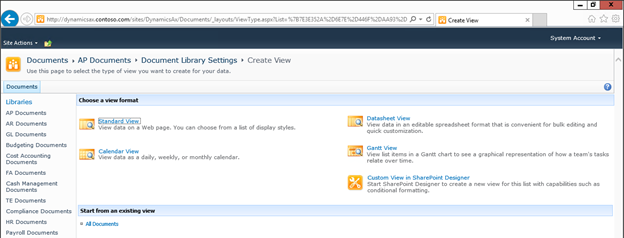
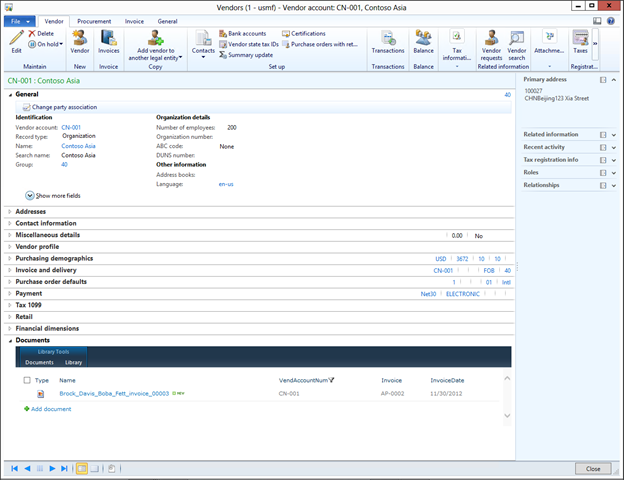
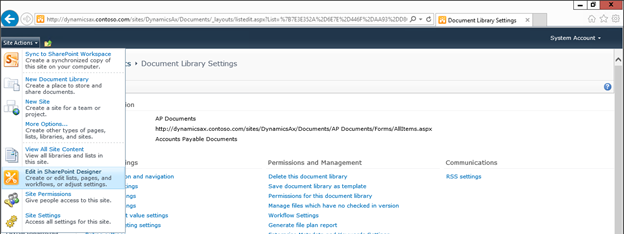
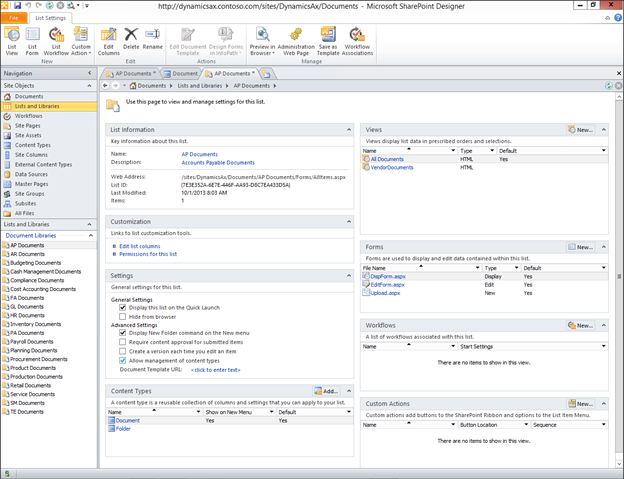
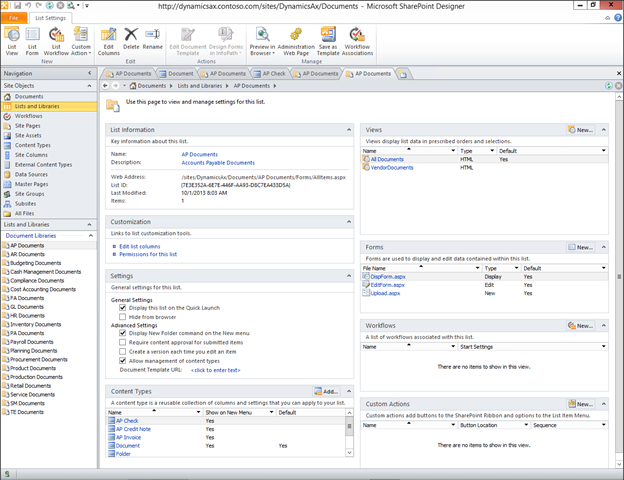
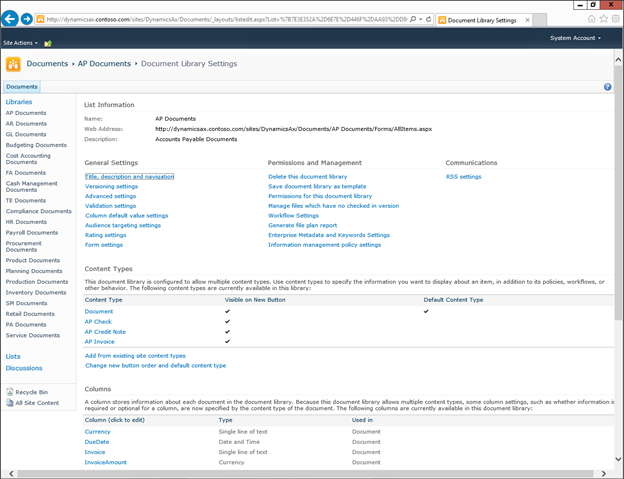
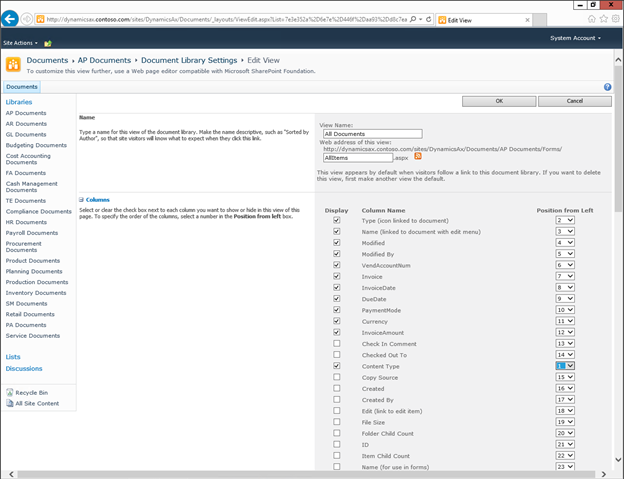
 Create new SharePoint 2013 empty project
Create new SharePoint 2013 empty project Deploy the SharePoint site as a farm solution
Deploy the SharePoint site as a farm solution SharePoint solution items
SharePoint solution items Adding new item to SharePoint solution
Adding new item to SharePoint solution Adding new item of type site column to the solution
Adding new item of type site column to the solution Adding new item of type Content Type to SharePoint solution
Adding new item of type Content Type to SharePoint solution Specifying the base type of the content type
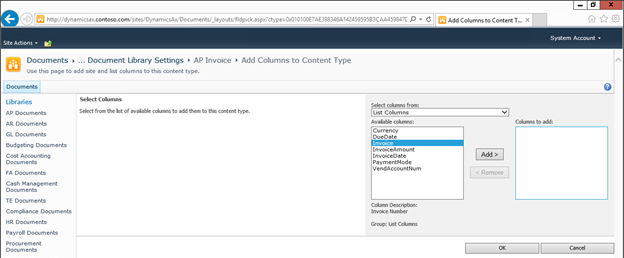
Specifying the base type of the content type Adding columns to the content type
Adding columns to the content type Adding new module to SharePoint solution.
Adding new module to SharePoint solution.
 Adding existing content type to the pages library
Adding existing content type to the pages library Selecting the content type to add it to pages library
Selecting the content type to add it to pages library Adding new document of the news content type to pages library
Adding new document of the news content type to pages library Creating new page of news content type to pages library.
Creating new page of news content type to pages library.

 Visual Studio 2010 then asks you to create an additional web application, which hosts the Silverlight application. It’s important to select the checkbox Enable WCF RIA Services (see screenshot below):
Visual Studio 2010 then asks you to create an additional web application, which hosts the Silverlight application. It’s important to select the checkbox Enable WCF RIA Services (see screenshot below): After clicking the Ok button, Visual Studio generates a solution with two projects, one Silverlight 4 project and one ASP.NET project. In the next section, we will create the SAP data access layer using the LINQ to SAP designer.
After clicking the Ok button, Visual Studio generates a solution with two projects, one Silverlight 4 project and one ASP.NET project. In the next section, we will create the SAP data access layer using the LINQ to SAP designer. LINQ to SAP is internally called LINQ to ERP.
LINQ to SAP is internally called LINQ to ERP. Enter the connection data for your SAP R/3 system and then click the Ok button. Next, search for and select the SAP function module named
Enter the connection data for your SAP R/3 system and then click the Ok button. Next, search for and select the SAP function module named  In the above function dialog, change the method name to
In the above function dialog, change the method name to  After clicking the Ok button and saving the ERP file, the LINQ designer will generate a
After clicking the Ok button and saving the ERP file, the LINQ designer will generate a  On the LINQ designer level (click on the free part of the LINQ designer surface) property, Create Object Outside Of Context Class must be set to
On the LINQ designer level (click on the free part of the LINQ designer surface) property, Create Object Outside Of Context Class must be set to  Now, we finally add a
Now, we finally add a  That’s it! We now have our SAP data access layer ready to use and can start adding the domain service in the next section.
That’s it! We now have our SAP data access layer ready to use and can start adding the domain service in the next section. In the upcoming dialog, create an empty domain service class by just clicking the Ok button:
In the upcoming dialog, create an empty domain service class by just clicking the Ok button: Next, we add the service operation
Next, we add the service operation  That’s all we need on the server side.
That’s all we need on the server side. The next screenshot shows the final result:
The next screenshot shows the final result: That’s it.
That’s it.![ppt_img[1]](https://sharepointsamurai.files.wordpress.com/2014/10/ppt_img1.gif)
![sap_integration_en_round[1]](https://sharepointsamurai.files.wordpress.com/2014/09/sap_integration_en_round1.jpg)



![Windows_Azure_Wallpaper_p754[1]](https://sharepointsamurai.files.wordpress.com/2014/09/windows_azure_wallpaper_p7541.jpg)
![office365logoorange_web[1]](https://sharepointsamurai.files.wordpress.com/2014/09/office365logoorange_web1.png)
 Prerelease content
Prerelease content












![bottlenecks[1]](https://sharepointsamurai.files.wordpress.com/2014/09/bottlenecks1.jpg?w=300&h=196)

































![winjs_life_02[1]](https://sharepointsamurai.files.wordpress.com/2014/07/winjs_life_021.png)




 aution
aution![Visual-Studio-2010-Add-New-Project[1]](https://sharepointsamurai.files.wordpress.com/2014/07/visual-studio-2010-add-new-project1.png)
![visual-studio-11-output-directory[1]](https://sharepointsamurai.files.wordpress.com/2014/07/visual-studio-11-output-directory1.png)

 Security Note
Security Note



![uml+activity+diagram+library+mgmt+book+return[1]](https://sharepointsamurai.files.wordpress.com/2014/06/umlactivitydiagramlibrarymgmtbookreturn1.jpg "activity diagram")


![ImageGen[1]](https://sharepointsamurai.files.wordpress.com/2014/06/imagegen1.png)







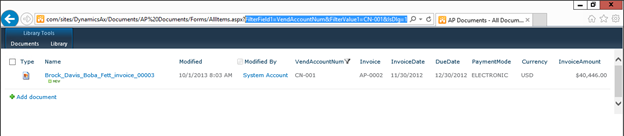
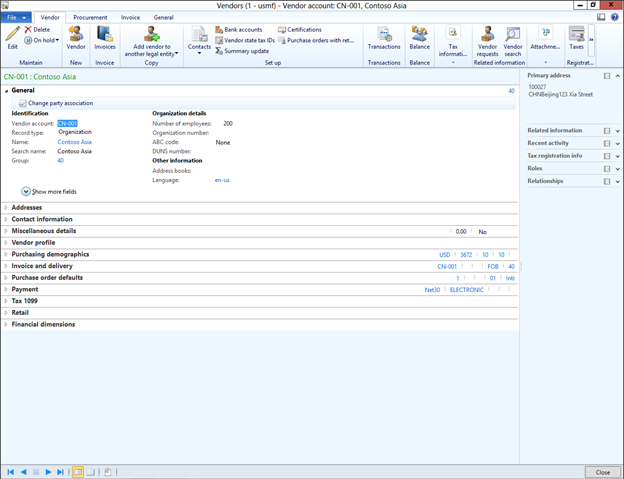


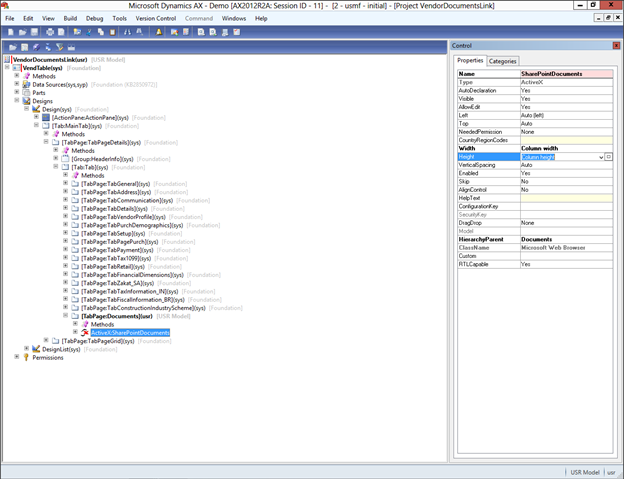
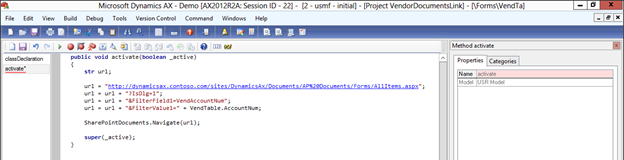
























![sap2[1]](https://sharepointsamurai.files.wordpress.com/2014/05/sap21.jpg?w=474&h=235)
![SQL+Server+2014+Evolution[1]](https://sharepointsamurai.files.wordpress.com/2014/05/sqlserver2014evolution1.png?w=474)







































































 Important
Important



























































 in the Insert Formula dialog box")

 in Insert Formula dialog box")

































































