![SharePointOnline2L-1[1]](https://sharepointsamurai.files.wordpress.com/2014/09/sharepointonline2l-11.png)
| Planning and deploying SharePoint Online |
Note In Office 365 plans, software boundaries and limits for SharePoint Online are managed separately from mailbox storage limits. Mailbox storage limits are set up and managed by using Exchange Online. For more information about how Exchange manages mailbox limits, see Mailbox types and storage limits for Recipients.
- SharePoint Online feature availability
- Limits in SharePoint Online in Office 365 plans
- Limits for site elements in SharePoint Online
- Additional information about OneDrive for Business limits
- Additional Resources
![SharePointOnline2L-1[1]](https://sharepointsamurai.files.wordpress.com/2014/09/sharepointonline2l-111.png)
SharePoint Online Feature availability
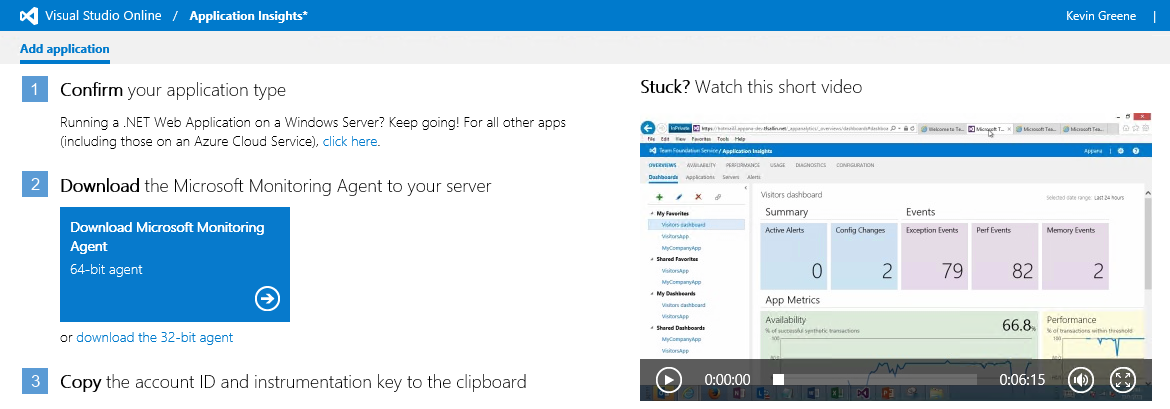
Need help determining which SharePoint solution best fits your organization’s needs?
The various Office 365 plans include different SharePoint Online offerings. These include:
- SharePoint Online for Office 365 Small Business
- SharePoint Online for Office 365 Midsize Business
- SharePoint Online for Office 365 Enterprise, Education, and Government
You can choose the plan that best fits your organization’s needs. Each person who accesses the SharePoint Online service must be assigned to a subscription plan. SharePoint Online can be included in a Microsoft Office 365 plan, or it can be purchased as a standalone plan, such as SharePoint Enterprise Plan 1 or SharePoint Enterprise Plan 2.
Limits in SharePoint Online in Office 365 plans
In this section:
- Limits for SharePoint Online for Office 365 Small Business
- Limits for SharePoint Online for Office 365 Midsize Business
- Limits for SharePoint Online for Office 365 Enterprise, Education, and Government
Limits for SharePoint Online for Office 365 Small Business
SharePoint Online Small Business and SharePoint Online Small Business Premium have common boundaries and limits. The following table describes those limits.
| Feature | Description |
|---|---|
| Storage per user (contributes to total storage base of tenant) | 500 megabytes (MB) per subscribed user. |
| Site collection quota limit | Up to 1 TB per site collection. (25 GB for a trial).
5,000 items in site libraries, including files and folders. The minimum storage allocation per site collection is 100 MB. |
| Site collections (#) per tenant | 1 site collection per tenant. |
| Subsites | Up to 2,000 subsites per site collection |
| Total available tenant storage | 10 GB + 500 MB per user.
For example, if you have 10 users, the base storage allocation is 15 GB (10 GB + 500 MB * 10 users). You can purchase additional storage up to a maximum of 1TB. |
| Personal site storage | 1 TB per user, as soon as provisioned.
This amount is counted separately, and does not add to or subtract from the overall storage allocation for a tenant. Personal site storage applies to a user’s OneDrive for Business library and personal newsfeed. For more information, see Additional information about OneDrive for Business limits. |
| Public Website storage default | 5 GB
A SharePoint admin can allocate up to 1 TB (the limit for a site collection). |
| File upload limit | 2 GB per file. |
| File attachment size limit | 250 MB |
| Sync limits | 20,000 items in the OneDrive for Business library, including files and folders.
5,000 items in site libraries, including files and folders. |
| Number of users | 1 – 25 users |
| Number of external users invitees | There is no limit to number of external users you can invite to your SharePoint Online site Collections. For more information, see Manage external sharing for your SharePoint Online environment |
When reviewing the information on the previous table, remember that the base storage limits for Office 365 for Small Business (10 GB + 500 MB per subscribed user) will affect some of these values. For example, although SharePoint Online for Small Business imposes a limit of 1 TB per site collection, your particular tenant might not have enough storage available to contain a site collection of 1 TB.
Important It’s a good idea to monitor the Recycle Bin and empty it regularly. Content in the Recycle Bin is counted against the storage quota for a tenant. For example, if the Recycle Bin on a site contains 5 GB of content, that 5 GB is subtracted from the available storage.
Limits for SharePoint Online for Office 365 Midsize Business
The following table shows the software boundaries and limits for the SharePoint Online Midsize Business plan.
| Feature | Description |
|---|---|
| Storage per user (contributes to total storage base of tenant) | 500 megabytes (MB) per subscribed user. |
| Storage base per tenant | 10 GB + 500 MB per subscribed user.
For example, if you have 250 users, the base storage allocation is 135 GB (10 GB + 500 MB * 250 users). You can purchase additional storage up to a maximum of 20 TB. |
| Additional storage at a cost per GB per month. | To buy storage, see Change storage space for your subscription.
Important You can’t buy additional storage for a trial subscription. |
| Site collection quota limit | Up to 1 TB per site collection. (25 GB for a trial).
5,000 items in site libraries, including files and folders. SharePoint admins can set storage limits for site collections and sites. The minimum storage allocation per site collection is 100 MB. |
| Site collections (#) per tenant | 20 site collections (other than personal sites). |
| Subsites | Up to 2,000 subsites per site collection. |
| Personal site storage | 1TB per user, as soon as provisioned.
Personal site storage applies to a user’s OneDrive for Business library and personal newsfeed. This amount is counted separately, and does not add to or subtract the overall storage allocation for a tenant. For more information about OneDrive for Business, see Additional information about OneDrive for Business limits later in this article. |
| Public Website storage default | 5 GB
A SharePoint admin can allocate up to 1 TB (the limit for a site collection). |
| File upload limit | 2 GB per file. |
| File attachment size limit | 250 MB |
| Sync limits | 20,000 items in the OneDrive for Business library, including files and folders.
5,000 items in site libraries, including files and folders. |
| Number of users | 1 – 250 users |
| Number of external user invitees | There is no limit to number of external users you can invite to your SharePoint Online site Collections. For more information see, Manage external sharing for your SharePoint Online environment |
When reviewing the information on the previous table, remember that the base storage limits for Office 365 for Midsize Business (10 GB + 500 MB per subscribed user) will affect some of these values. For example, although SharePoint Online for Midsize Business imposes a limit of 1 TB per site collection and a limit of 20 site collections, your particular tenant might not have enough storage available to contain 20 site collections of 1 TB each.
Important It’s a good idea to monitor the Recycle Bin and empty it regularly. Content in the Recycle Bin is counted against the storage quota for a tenant. For example, if the Recycle Bin on a site contains 25 GB of content, that 25 GB is subtracted from the available storage.
Limits for SharePoint Online for Office 365 Enterprise, Education, and Government
One or more Office 365 subscriptions plans can be included as part of your subscription. This is true for the following plan offerings:
- Microsoft Office 365 Enterprise subscriptions (E1 – E4)
- Microsoft Office 365 Government subscriptions (G1 – G4)
- Microsoft Office 365 Education subscriptions (A2 – A4)
- Microsoft Office 365 Kiosk subscriptions (K1-K2)
- SharePoint Online stand-alone subscription plans (Plan 1 and Plan 2).
These plans have common boundaries and limits. The following table describes those limits.
| Feature | Office 365 Enterprise plans (including E1 – E4, A2-A4, G1-G4, and SharePoint Online Plan 1 and Plan 2) | Office 365 Kiosk plans (Enterprise and Government K1 – K2) |
|---|---|---|
| Storage per user (contributes to total storage base of tenant) | 500 megabytes (MB) per subscribed user. | Zero (0).
Licensed Kiosk Workers do not add to the tenant storage base. |
| Additional storage (per GB per month); no minimum purchase | To buy storage, see Change storage space for your subscription.
Important You can’t buy additional storage for a trial subscription. |
To buy storage, see Change storage space for your subscription.
Important You can’t buy additional storage for a trial subscription. |
| Storage base per tenant | 10 GB + 500 MB per subscribed user + additional storage purchased.
For example, if you have 10,000 users, the base storage allocation is approximately 5 TB (10 GB + 500 MB * 10,000 users). You can purchase an unlimited amount of additional storage. Important If you have a Government Community Cloud plan, you can purchase additional storage up to 25 TB. |
10 GB + additional storage purchased.
You can purchase an unlimited amount of additional storage. Important If you have a Government Community Cloud plan, you can purchase additional storage up to 25 TB. |
| Site collection storage limit | Up to 1 TB per site collection. (25 GB for trial).
SharePoint admins can set storage limits for site collections and sites. The minimum storage allocation per site collection is 100 MB. 5,000 items in site libraries, including files and folders. Important If you have a Government Community Cloud plan, the limit is 100 GB. |
Up to 1 TB per site collection. (25 GB for a trial). SharePoint admins can set storage limits for site collections and sites. The minimum storage allocation per site collection is 100 MB.
Important If you have a Government Community Cloud plan, the limit is 100 GB. Kiosk workers (plans K1-K2) cannot administer SharePoint site collections. You will need a license for at least one Enterprise plan user to manage Kiosk site collections. |
| Site collections (#) per tenant | 500,000 site collections (other than personal sites). | 500,000 site collections. |
| Subsites | Up to 2,000 subsites per site collection | Up to 2,000 subsites per site collection |
| Personal site storage | 1 TB per user (100 GB for government plans), as soon as provisioned.
Personal site storage applies to a user’s OneDrive for Business library and personal newsfeed. This amount is counted separately, and does not add to or subtract the overall storage allocation for a tenant. For more information about OneDrive for Business, see Additional information about OneDrive for Business limits later in this article. |
Not available. |
| Public Website storage default | 5 GB
A SharePoint admin can allocate up to 1 TB (the limit for a site collection). |
5 GB
A SharePoint admin can allocate up to 1 TB (the limit for a site collection). Kiosk workers (plans K1-K2) cannot administer Sharepoint site collections. You will need a license for at least one Enterprise plan user to manage Kiosk site collections. |
| File upload limit | 2 GB per file. | 2 GB per file. |
| File attachment size limit | 250 MB | 250 MB |
| Sync limits | 20,000 items in the OneDrive for Business library, including files and folders.
5,000 items in site libraries, including files and folders. |
20,000 items in the OneDrive for Business library, including files and folders.
5,000 items in site libraries, including files and folders. |
| Maximum number of users per tenant | 1 – 500,000+
Note If you have more than 500,000 users, please contact the Microsoft representative to discuss detailed requirements. |
1 – 500,000+
Note If you have more than 500,000 users, please contact the Microsoft representative to discuss detailed requirements. |
| Number of external user invitees | There is no limit to number of external users you can invite to your SharePoint Online site Collections. For more information, see Manage external sharing for your SharePoint Online environment | There is no limit to number of external users you can invite to your SharePoint Online site Collections. For more information, see Manage external sharing for your SharePoint Online environment |
When reviewing the information on the previous table, remember that the base storage limits for Office 365 for Enterprises (10 GB + 500 MB per subscribed user) will affect some of these values. For example, although SharePoint Online for Enterprise plans imposes a limit of 1 TB per site collection and a limit of 500,000 site collections, your particular tenant might not have enough storage available to contain 500,000 site collections of 1 TB each.
Important It’s a good idea to monitor the Recycle Bin and empty it regularly. Content in the Recycle Bin is counted against the storage quota for a tenant. For example, if the Recycle Bin on a site contains 25 GB of content, that 25 GB is subtracted from the available storage.
Limits for site elements in SharePoint Online
There are also limits for site elements of a SharePoint Online site. Here are some examples:
- List and Library limits Different types of columns have different limitations. For example, you can have up to 276 columns in a list for columns that contain a single line of text.
- Page limits You can add up to 25 Web Parts to a single wiki or web page.
- Security limits Different security features have different limits. For example, a single user can belong to no more than 5,000 security groups.
The specific elements for the previous site elements are too numerous to list here, but you can learn more about them in the TechNet article Software Boundaries and Limits for SharePoint 2013. In this linked article, only the sections on List and Library Limits, Page Limits, and Security Limits apply to SharePoint Onl
Additional information about OneDrive for Business limits
Each user in SharePoint Online for Office 365 gets an individual storage allocation of 1 TB for personal site content (100 GB for government plans). Personal sites include the user’s OneDrive for Business library, a Recycle Bin, and personal newsfeed information.
All SharePoint Online in Office 365 plans include the same storage allocation for individual personal sites. This storage allocation is separate from the tenant allocation.
For more information about how users can manage their individual OneDrive for Business allocation, see OneDrive for Business library limits.
Additional Resources
| For information about this: | Go here: |
|---|---|
| Office 365 connectivity limits | To learn more about Internet bandwidth, port and protocol considerations for Office 365 plans, see Office 365 Ports and Protocols. |
| SharePoint feature availability | To learn more about SharePoint feature availability and the SharePoint Online service in Office 365, see SharePoint Online Service Descriptions. |
| SharePoint Online search limits | To learn more about the search limits for SharePoint Online, see Search limits for SharePoint Online. |
| Mobile devices | To learn more about opening a SharePoint Online site from a mobile device, see Use a mobile device to work with SharePoint Online sites. |
| File types | To learn about file types that you can’t add to a list, see Types of files that cannot be added to a list or library. |
| Online URLs | To learn about SharePoint Online addresses, see SharePoint Online URLs and IP Addresses. |
| Site languages | To learn how to set language for your sites, see Change your language and region settings. |
| Planning and deploying SharePoint Online | |
| Change storage space |
Important You can’t buy additional storage for a trial subscription. |

























![ImageGen[1]](https://sharepointsamurai.files.wordpress.com/2014/06/imagegen1.png)













 +
+ ![microsoft_crm_wallpaper_02[1]](https://sharepointsamurai.files.wordpress.com/2014/06/microsoft_crm_wallpaper_021.jpg?w=167&h=125)


![sap2[1]](https://sharepointsamurai.files.wordpress.com/2014/05/sap21.jpg)




































 In cloud computing, fabric is a frequently used term. It is nevertheless not a product, nor a packaged solution that we can simply unwrap and deploy.
In cloud computing, fabric is a frequently used term. It is nevertheless not a product, nor a packaged solution that we can simply unwrap and deploy.  Similar to what is in Windows Azure Platform, fabric in
Similar to what is in Windows Azure Platform, fabric in  virtual machines can be deployed based on authorization and service configurations. Library servers are the repositories of building blocks like images, iso files, templates, etc. for composing VMs. To automatically deploy images and boot a VM from bare-metal remotely via networks, pre-boot execution environment (PXE) servers are used to initiate the operating system installation on a physical computer. Update servers like WSUS are for servicing VMs automatically and based on compliance policies. For interoperability, VMM 2012 admin console can add VMware vCenter Servers to enable the management of VMware ESX hosts. And of course, the consoles will have visibility to all authorized VMM servers which forms the backbone of Microsoft virtualization management solution.
virtual machines can be deployed based on authorization and service configurations. Library servers are the repositories of building blocks like images, iso files, templates, etc. for composing VMs. To automatically deploy images and boot a VM from bare-metal remotely via networks, pre-boot execution environment (PXE) servers are used to initiate the operating system installation on a physical computer. Update servers like WSUS are for servicing VMs automatically and based on compliance policies. For interoperability, VMM 2012 admin console can add VMware vCenter Servers to enable the management of VMware ESX hosts. And of course, the consoles will have visibility to all authorized VMM servers which forms the backbone of Microsoft virtualization management solution. based on selected criteria like connectivity properties, service-level agreements (SLAs), etc. By default, when adding a Hyper-V host to a VMM 2012 server, VMM 2012 automatically creates logical networks that match the first DNS suffix label of the connection-specific DNS suffix on each host network adapter.
based on selected criteria like connectivity properties, service-level agreements (SLAs), etc. By default, when adding a Hyper-V host to a VMM 2012 server, VMM 2012 automatically creates logical networks that match the first DNS suffix label of the connection-specific DNS suffix on each host network adapter. With VMM 2012 admin console, an administrator can discover, classify, and provision remote storage on supported storage arrays.
With VMM 2012 admin console, an administrator can discover, classify, and provision remote storage on supported storage arrays. 







![designmanager[1]](https://sharepointsamurai.files.wordpress.com/2014/03/designmanager1.png)














 Note
Note












 Important
Important










 Figure 1. Select SAP in the Attach Data Source Wizard
Figure 1. Select SAP in the Attach Data Source Wizard Figure 2. Enter connection information in the Attach Data Source Wizard
Figure 2. Enter connection information in the Attach Data Source Wizard Figure 3. Select the BusinessPartner and Product entities in the Attach Data Source Wizard
Figure 3. Select the BusinessPartner and Product entities in the Attach Data Source Wizard Figure 4. Entity Designer showing the Product entity
Figure 4. Entity Designer showing the Product entity
 Figure 5. Properties on the BusinessPartner entity have been set to the appropriate business type
Figure 5. Properties on the BusinessPartner entity have been set to the appropriate business type Figure 6. The ProductDetail entity
Figure 6. The ProductDetail entity Figure 7. Adding a relationship
Figure 7. Adding a relationship Figure 8. Configuring the relationship
Figure 8. Configuring the relationship Figure 9. Adding a new Common Screen Set
Figure 9. Adding a new Common Screen Set Figure 10. Writing “created” code on the AddEditProduct screen
Figure 10. Writing “created” code on the AddEditProduct screen Figure 11. Control layout
Figure 11. Control layout Figure 12. Changing Product Pic Url to an Image control
Figure 12. Changing Product Pic Url to an Image control Figure 13. Properties of the Product Pic Url control
Figure 13. Properties of the Product Pic Url control Figure 14. The ViewProduct screen
Figure 14. The ViewProduct screen Figure 15. The AddEditProduct screen
Figure 15. The AddEditProduct screen
 Figure 1. The Contoso Electronics website displayed on a desktop device
Figure 1. The Contoso Electronics website displayed on a desktop device Figure 2. The Contoso Electronics website displayed on mobile devices
Figure 2. The Contoso Electronics website displayed on mobile devices Figure 3. Device channels configured for a public-facing website built on SharePoint 2013
Figure 3. Device channels configured for a public-facing website built on SharePoint 2013

















 context
context  gear
gear ")
 Important
Important




















 Step 2:
Step 2:



















.png "Output of the Program with No Logging")
.png "Execution of the Logging Program with a Decorator")
.png "Program Execution with Dynamic Proxy")
.png "Output of the Program Using Two Proxies")
.png "Output with a Filtered Proxy")
