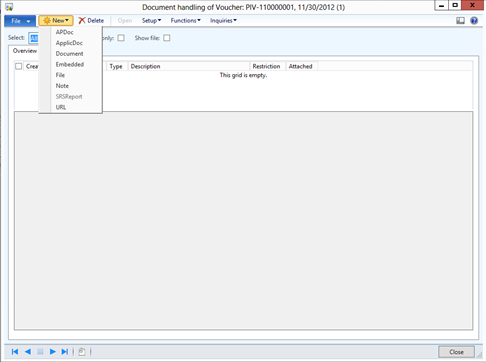
What is a lab environment?
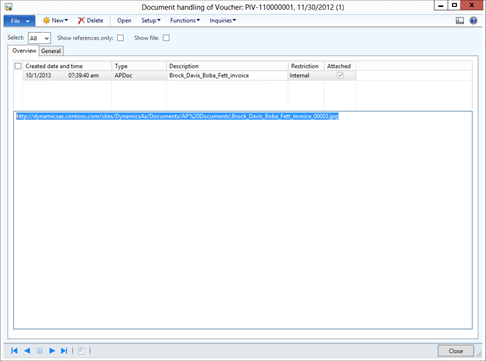
A lab environment is a collection of computers that are managed as a single unit, and on which you deploy the system under test along with test software. Here is a typical configuration of machines in a lab environment:
.png")
Typical lab environment configuration
This one is set up for automated tests of an ice cream vending service. The software product itself consists of a web service that runs on Internet Information Services (IIS) and a database that runs on a separate machine. The tests drive a web browser on a client machine.
With a lab environment, you can run a build-deploy-test workflow in which you can automatically build your system, deploy its components to the appropriate machines in the environment, run the tests, and collect test data. (The fully automated version of this is described in Chapter 5, “Automating System Tests.”)
The workflow is controlled by a test controller with the help of test agents installed on each test machine. The test controller runs on a separate computer.
Now you might ask why you need lab environments, since you could deploy your system and tests to any machines you choose.
Well, you could, but lab environments make several things easier:
- You can set up automated build-deploy-test workflows. The scripts in the workflow use the lab role names of the machines, such as “Web Client,” so that they are independent of the domain names of the computers.
- The results of tests can be shown on charts that relate them to requirements.
- Lab Manager automatically installs test agents on each machine, enabling test data to be collected. Lab Manager manages the test settings of the virtual environment, which define what data to collect.
- You can view the consoles of the machines through a single viewer, switching easily from one machine to the other.
- Lab environments manage the allocation of machines to tests for reasons that include preventing two team members from mistakenly assigning the same machine to different tests.
Lab environments come in two varieties. A standard lab environment (roughly equivalent to a physical environment in Visual Studio 2010) can be composed of any computers that you have available, such as physical computers or virtual machines running on third-party frameworks.
An SCVMM environment is made up entirely of virtual machines controlled by System Center Virtual Machine Manager (SCVMM). SCVMM environments provide you with several valuable facilities; they allow you to:
- Create fresh test environments within minutes. You can store a complete environment in a library and deploy running copies of it. For example, you could store an environment of three machines containing a web client, a web server, and a database. Whenever you want to test a system in that configuration, you deploy and run a new instance of it.
- Take snapshots of the states of the machines. For example whenever you start a test, you can revert to a snapshot that you took when everything was freshly installed. Also, when you find a bug, you can take a snapshot of the environment for later investigation.
- Pause and resume all the virtual machines in the environment at the same time.
Standard environments are useful for tests that have to run on real hardware, such as some kinds of performance tests. You can also use them if you haven’t installed SCVMM or Hyper-V, as would be the case if, for example, you already use another virtualization framework. But as you can see, we think there are great benefits to using SCVMM environments.
Stored SCVMM environments
Because you can store them in a library, SCVMM environments help to make your tests repeatable; when you run them for the next build, or when a new release is planned after a six-month break, you can be sure that the tests are running under the same conditions.
.png")
A stored SCVMM environment
For example, on Fabrikam’s ice cream sales project, the team often wants to deploy and test a new build of the sales system. It has several components that have to be installed on different machines. Of course, the sales system software is a new build each time. But the platform software, such as operating system, database, and web browser don’t change.
So at the start of the project, the team creates an environment that has the platform software, but no installation of the ice cream system. In addition, each machine has a test agent. The Fabrikam team stores this environment in the library as a template.
Whenever a new build is to be tested, a team member selects the stored platform environment, and chooses Deploy. Lab Manager takes a few minutes to copy and start the environment. Then they only have to install the latest build of the system under test.
While an environment is running, its machines execute on one or more virtualization hosts that have been set up by the system administrator. The stored version from which new copies can be deployed is stored on an SCVMM library server.
Lab management with third-party virtualization frameworks
Some teams have already invested in other virtualization frameworks such as VMware or Citrix XenServer. If that is your situation, the case for switching to Hyper-V and SCVMM might be less clear. But even if you don’t install SCVMM or Hyper-V, you can still use Lab Manager by using standard environments.
With standard environments, you get many of the benefits of lab management, but without the ability to save and quickly set up fresh environments. Instead, you’d have to use your third-party machine manager to set up new machines.
When you assign a machine to a standard environment, Lab Manager will automatically install a test agent and couple it to your test controller. This makes the machine ready for an automatic build-deploy-test workflow and for test data collection. (In Visual Studio 2010, you have to install the test agent manually, but coupling it to the test controller is automatic.)
How to use lab environments
Prerequisites
To enable your team to use lab environments, you first have to set up:
- Visual Studio Team Foundation Server, with the Lab Manager feature enabled.
- A test controller, linked to your team project in Team Foundation Server.
- (Preferable, but not mandatory) System Center Virtual Machine Manager (SCVMM) and Hyper-V.
You only need to set up these things once for the whole team, so we have put the details in the Appendix. If someone else has kindly set up SCVMM, Lab Manager, and a test controller, just continue on here.
Lab center
You manage environments by using Lab Center, which is part of Microsoft Test Manager (MTM). MTM is installed as part of Visual Studio Ultimate or Test Professional. You’ll find it on the Windows Start menu under Visual Studio. If it’s your first time using it, you’ll be asked for the URL of your team project collection. Switch to the Lab Center view (it’s the alternative to Test Center). On the Environments page, you’ll see a list of environments that are in use by your team. Some of them might be marked “in use” by individual team members:
.png")
Managing environments in Lab Center
(Use the Home button if you want to switch to another team project.)
More information is available from the MSDN website topic: Getting Started with Lab Management.
Connecting to a lab environment
If your team has been using lab environments for a while, then when you open Lab Center, you might already see some environments that are available to use. Pick an environment with a status of Ready, without an In Use flag, and that looks as if it has the characteristics you want, which ought to be indicated by its name. Select it and choose Connect.
The Environment View opens. From here you can log into any of the machines in the environment.
.png")
The environment view
Typically, a deployed environment will have a recent build of your system already installed. If you’re sure that it’s free for you to use, you could decide to run some tests on it. However, make sure you know your team’s conventions; for example, if the environment’s name contains the name of a team member, ask if it is ok to use.
Using a deployed (running) environment
Log in. Choose the Connect button to open a console view of the environment. From there you can log into any of its machines. More about the Connect button can be found on MSDN in the topic How to: Connect to a Virtual Environment.
Reserve the environment. You can mark it as In Useto discourage other team members from interfering with it. This doesn’t prevent access by others, but simply sets a flag in Lab Center.
Revert a virtual environment to a clean snapshot. In the environment viewer, look at the Snapshots tab. If the Snapshots tab isn’t available, then this is a standard environment composed of existing machines. You might need to make sure that the latest version of your system is installed.
In a virtual environment, the team member who created the environment should have made a snapshot immediately after installing the system under test. Select the snapshot and restore the environment to that state. If there isn’t a snapshot available, that’s (hopefully) because the previous user has already restored it to the clean state. Again, you might need to check the conventions of your team.
Explore and test your system. Now you can start testing your system, which is the topic of the next chapter.
Restore the snapshot when you’re done with a virtual environment, to restore it to the newly installed state. This makes it easier for other team members to use. This option isn’t available for standard environments, so you might want to clean up any test materials that you have created.
Clear the “in use” flag when you’re done.Typically, a team will keep a number of running environments that contain a recent build, and share them. Reusing the environment and restoring it to its initial snapshot is the quickest way of assigning an environment for a test run.
Deploying an environment
If there is no running environment that is suitable for what you want to do, you can look for one in the library. The library contains a selection of stored virtual environments that have previously been created by your colleagues. You can learn more from the topic: Using a Virtual Lab for Your Application Lifecycle, on MSDN.
.png")
The environment library in MTM Lab Center
(If the library isn’t available, that might mean that your team has not set Lab Manager to use SCVMM. But you can still create standard environments, which are made up of computers not controlled by SCVMM. Skip to the section about them near the end of this chapter. Alternatively, you could set up SCVMM as we describe in the Appendix.)
Environments stored in the library are templates; you can’t connect to one because its virtual machines aren’t running. Instead, you must first deploy it. Deploying copies the virtual machines from the library to the virtual machine host, and then starts them.
In MTM, in Lab Center, choose Deploy. Choose an environment from the list. They should have names that help you decide which one you want.
After you have picked an environment, Lab Center takes a few minutes to copy the virtual machines and to make sure that the test agents (which help deploy software and collect data) are running.
Eventually the environment is listed under the Lab tab as Ready (or Running in Visual Studio 2010). Then you’re all set to use it. If it shows up as Not Ready, then try the Repair command. This reinstalls test agents and reconnects them to your test controller. In most cases that fixes it.
Install your system
Typically, stored environments contain installations of the base platform: operating systems, databases, and so on. They don’t usually include an installation of the system under test. Your next step is therefore to install the latest build of your system.
To help choose a good recent build, open the build status report in your web browser. The URL is similar to http://contoso-tfs:8080/tfs/web. Click on Builds. You might have to set the date and other filters. The quality and location of each build is summarized.
In Lab Center, under the Lab tab, select the running environment and choose Connect. Log into the environment’s machines.
Use the installer (typically an .msi file) that is generated by the build process. The location can be obtained from the build status reports. Pick an installer that was generated from the Debug build configuration. You need to put each component on the right machine. Each machine has a role name such as Client, Web Server, or Database, to help you make the right choice.
Later we’ll discuss how you can write scripts to automate the deployment of the system under test.
Review the name you gave to the environment to make sure it reflects the system and build you installed.
Take a snapshot of the environment
Create a snapshot of the environment. This will enable subsequent users to get the environment back to its nice clean state. Do this immediately after you have installed your system, and before you run any tests, other than perhaps a quick smoke test to make sure the installation is OK.
You can create a snapshot either from the Snapshots tab in Environment Viewer, or from the context menu of the environment in the Lab listing.
Use it
After you’ve taken a snapshot, you can start using it as we described earlier. When you’ve finished testing, you can revert to the snapshot.
Delete it (eventually)
Delete an environment when the build it uses is superseded.
Creating a new virtual environment
What if there are no environments in the stored library, or none have the mix of machines you need? Then you’ll have to create one. And if you’re feeling generous, you could add it to the library for other team members to use.
You can either store an environment directly in the library, or you can create it as a running environment and then store it in the library. Storing directly is preferable if you don’t need to configure the constituent virtual machines in any way.
To add a new environment directly to the library, open MTM; choose Lab Center, Library, Environments, and then the New command.

Creating a new environment in the library
Alternatively, to create a new running environment that you can store later, choose Lab Center, Lab, and then New. In the wizard, choose SCVMM Environment. (In Visual Studio 2010, the New command has a submenu, New Virtual Environment.)
In either method, you continue through the wizard to choose virtual machines from the library. If your team has been working for a while, there should be a good stock of virtual machines. Their names should indicate what software is installed on them.
Choose library machines that have type Template if they are available. Unlike a plain virtual machine, you can deploy more than one copy of a template. This is because when a template VM is deployed, it gets a new ID so that there are no naming conflicts on your network. Using templates to create a stored environment allows more than one copy of it to be deployed at a time.
.png")
Creating a new virtual environment
You have to name each machine uniquely within your new lab environment. Notice that the name of the computer in the environment is not automatically the same as its name in the domain or workgroup.
You also have to assign a role name to each machine, such as Desktop Client or Web Server. More than one machine can have the same role name. There is a predefined set to choose from, but you can also invent your own role names. These roles are used to help deploy the correct software to each machine. If you automate the deployment process, you will use these names; if you deploy manually, they will just help you remember which machine you intended for each software component.
When you complete the wizard, there will be a few minutes’ wait while VMs are copied.
MTM should now show that your environment is in the library, or that it is already deployed as a running environment, depending on what method of creation you chose to begin with. If it’s in the library, you can deploy it as we described before.
After creating an environment, you typically deploy software components and then keep the environment in existence until you want to move to a new build. Different team members might use it, or you might keep it to yourself. You can mark an environment as “In Use” to discourage others from interfering with it while your work is in progress.
Stored and running machines
The lab manager library can store both individual virtual machines and complete environments. There are command buttons for creating new environments, storing them in the library, and for deploying environments from the library. You have to shut down an environment before you can store it.
.png")
Stored and deployed environments
Creating and importing virtual machines
You can store individual virtual machines from the test host to the library. Therefore, if your team starts off with a set of virtual machines in the library that include a basic set of platforms—for example, Windows 7 and Windows Server 2008—then you can deploy a machine in an environment, add extra bits, and then store it back in the library.
.png")
System Center Virtual Machine Manager (SCVMM)
But how do you create those first virtual machines? For this you need to access SCVMM, on which Lab Manager is based. It’s typically an administrator’s task, so you’ll find those details in the Appendix. Briefly:
- You can create a new machine in the SCVMM console and then install an operating system on it, either with your DVD or from your corporate PXE server.
- Every test machine needs a copy of the Team Foundation Server Test Agent, which you can get from the Team Foundation Server installation DVD.
- Use the SCVMM console to store the VM in the library as a template. This is preferable to storing it as a plain VM.
- In Lab Manager, use the Import command on the Library tab in order to make the SCVMM library items visible in the Lab Center library.
.png")
How environments are managed
Composed environments
A composed environment is made up of virtual machines that are already running. When you compose an environment from running machines, they are assigned to your environment; when you delete the environment, they are returned to the available pool. You can create a composed environment very quickly because there is no copying of virtual machines.
We recommend composed environments for quick exploratory tests of a recent build. The team should periodically place new machines in the pool on which a recent build is installed. Team members should remember to delete composed environments when they are no longer using them.
.png")
Composed environments
In Visual Studio 2012, you make a composed environment the same way you create a virtual environment: by choosing New and then SCVMM environment. In the wizard, you’ll see that the list of available machines includes both VM templates and running pool machines. If you want, you can mix pool machines and freshly created VMs both in the same environment. For example, you might use new VMs for your system under test, and a pool machine for a database of test data, or a fake of an external system. Because the external system doesn’t change, there is no need to keep creating new versions of it.
In Visual Studio 2010, use the New Composed Environment command and choose machines from the list.
Standard environments
Standard environments are made up of existing computers. They can be either physical or virtual machines, or a mixture. They must be domain-joined.
You can create standard environments even if your team hasn’t yet set up SCVMM. For example, if you are already using VMware to run virtual machines and don’t want to switch to Hyper-V and SCVMM, you can use Lab Manager to set up standard environments. You can’t stop, start, or take snapshots of standard environments, but Lab Manager will install test agents on them and you can use them to run a build-deploy-test workflow.
You can also use standard environments when it is important to use a real machine—for example, in performance tests.
To create a standard environment, click New and then choose Standard Environment.
(In Visual Studio 2010, choose New Physical Environment. You must manually install test and lab agents on the computers. These agents can be installed from the Team Foundation Server DVD.)
For an example, see Lab Management walkthrough using Visual Studio 11 Developer Preview Virtual Machine on the Visual Studio Lab Management team blog.
Summary
There’s a lot of pain and overhead in configuring physical boxes to build test environments. The task is made much easier by Visual Studio Lab Manager, particularly if you use virtual environments.
With Lab Manager you can:
- Manage the allocation of lab machines, grouping them into lab environments.
- Configure machines for the collection of test data.
- Rapidly create fresh virtual environments already set up with a base platform of operating system, database, and so on.
Differences between Visual Studio 2010 and Visual Studio 2012
- System Center Virtual Machine Manager 2012. Lab Management in Visual Studio 2012 works with SCVMM 2012 in addition to SCVMM 2008.
- Standard environments. Lab Manager in Visual Studio 2012 is easier to use with third-party virtualization frameworks as well as physical computers. It will install test agents if necessary.
- Test agents. In Visual Studio 2010, you must install test and lab agents on the machines that you want to use in the lab. In Visual Studio 2012, there is only one type of agent, and it is installed automatically by Lab Manager on each of the machines in a lab environment. You can still install the test agent yourself to save time when lab environments are created.
- Compatibility. Most combinations of 2010 and 2012 RC products work together. For example, you can create environments on Visual Studio Team Foundation Server 2010 using Microsoft Test Manager 2012 RC.
.png")

![kaizen%20not%20kaizan[1]](https://sharepointsamurai.files.wordpress.com/2014/09/kaizen20not20kaizan1.png)
![taking-your-version-control-to-a-next-level-with-tfs-and-git-1-638[1]](https://sharepointsamurai.files.wordpress.com/2014/09/taking-your-version-control-to-a-next-level-with-tfs-and-git-1-6381.jpg)


![2352.vs_5F00_heart_5F00_git_5F00_thumb_5F00_66558A9C[1]](https://sharepointsamurai.files.wordpress.com/2014/09/2352-vs_5f00_heart_5f00_git_5f00_thumb_5f00_66558a9c1.png)
![biztalk_adapter_2004-1[1]](https://sharepointsamurai.files.wordpress.com/2014/07/biztalk_adapter_2004-11.jpg)

 Note
Note
 Because you have all the components of BizTalk Adapter Service installed on the same computer, the URL for that service will be
Because you have all the components of BizTalk Adapter Service installed on the same computer, the URL for that service will be  The Add a Target wizard starts. Perform the following steps to create an LOB Target.
The Add a Target wizard starts. Perform the following steps to create an LOB Target. Click Next.
Click Next. Click OK. The schemas are added to the project under an LOB Schemas folder.
Click OK. The schemas are added to the project under an LOB Schemas folder. ] to open the Message Type Picker dialog box.
] to open the Message Type Picker dialog box. ], and then click OK. For this tutorial, select the Send schema (
], and then click OK. For this tutorial, select the Send schema (
 Important
Important

![8322.sharepoint_2D00_2010_5F00_4855E582[1]](https://sharepointsamurai.files.wordpress.com/2014/07/8322-sharepoint_2d00_2010_5f00_4855e5821.jpg)

 Tip:
Tip: 

























![ImageGen[1]](https://sharepointsamurai.files.wordpress.com/2014/06/imagegen1.png)









































![office365[1]](https://sharepointsamurai.files.wordpress.com/2014/05/office3651.png)