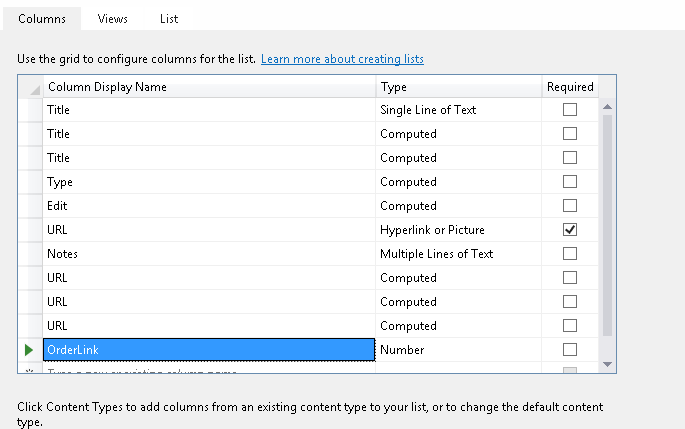
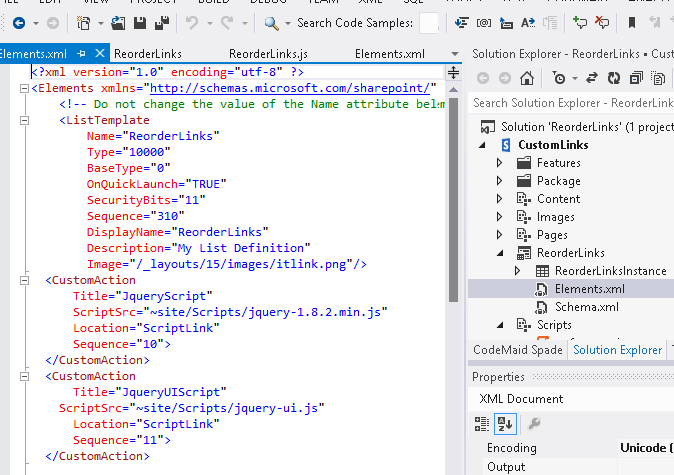
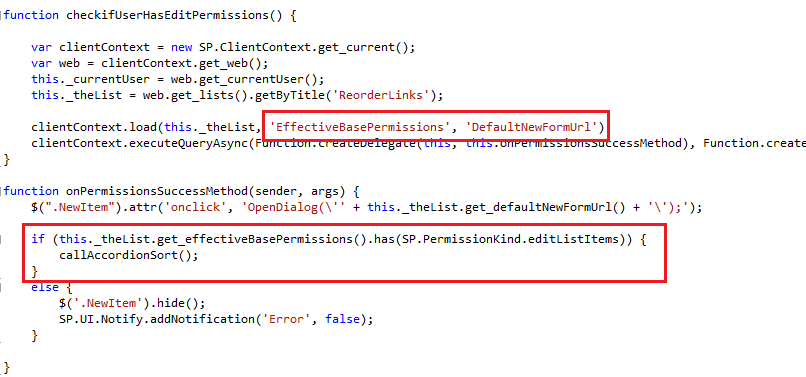
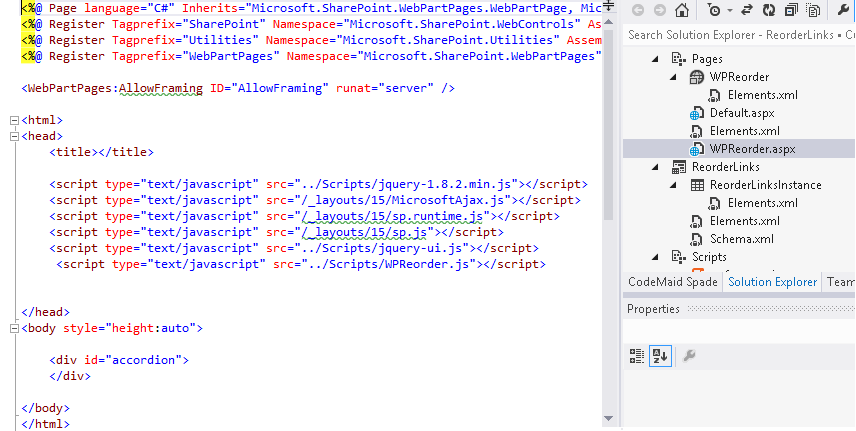
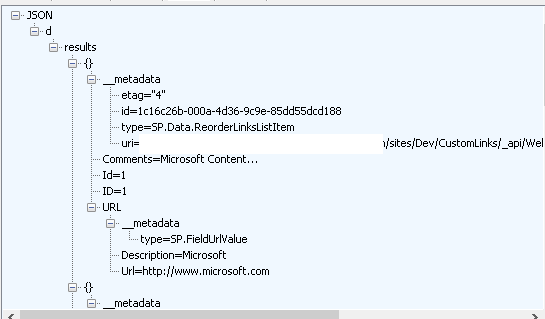
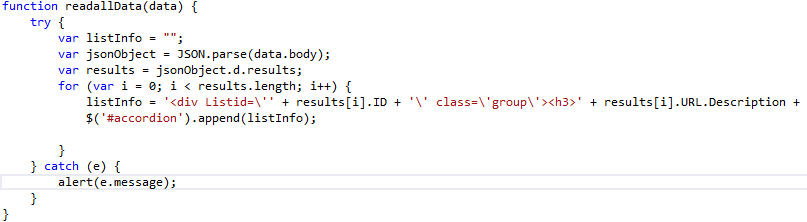
After my successful creation and implementation of an ALM for Business Connexion using the SharePoint Platform, I thought I’d share the lessons I have learned and show you step for step how you can implement your own ALM leveraging the power of the SharePoint Platform
![slide5[1]](https://sharepointsamurai.files.wordpress.com/2014/09/slide51.jpg?w=474)
In this article,
- An Overview : SharePoint Application Lifecycle Management:
- Learn how to plan and manage Application Lifecycle Management (ALM) in Microsoft SharePoint 2010 projects by using Microsoft Visual Studio 2010 and Microsoft SharePoint Designer 2010.
- Also learn what to consider when setting up team development environments,
- Establishing upgrade management processes,
- Creating a standard SharePoint development model.
- Extending your SharePoint ALM to include other Departments like Java, Mobile, .Net and even SAP Development
The Microsoft SharePoint 2010 development platform, which includes Microsoft SharePoint Foundation 2010 and Microsoft SharePoint Server 2010, contains many capabilities to help you develop, deploy, and update customizations and custom functionalities for your SharePoint sites. The activities that take advantage of these capabilities all fall under the category of Application Lifecycle Management (ALM).
Key considerations when establishing ALM processes include not only the development and testing practices that you use before the initial deployment of a single customization, but also the processes that you must implement to manage updates and integrate customizations and custom functionality on an existing farm.
This article discusses the capabilities and tools that you can use when implementing an ALM process on a SharePoint farm, and also specific concerns and things to consider when you create and hone your ALM process for SharePoint development.
This article assumes that each development team will develop a unique ALM process that fits its specific size and needs, so its guidance is necessarily broad. However, it also assumes that regardless of the size of your team and the specific nature of your custom solutions, you will need to address similar sets of concerns and use capabilities and tools that are common to all SharePoint developers.
The guidance in this article will help you as create a development model that exploits all the advantages of the SharePoint 2010 platform and addresses the needs of your organization.
Although the specific details of your SharePoint 2010 ALM process will differ according the requirements of your organizations, most development teams will follow the same general set of steps. Figure 1 depicts an example ALM process for a midsize or large SharePoint 2010 deployment. Obviously, the process and required tasks depend on the project size.

The following are the specific steps in the process illustrated in Figure 1 (see corresponding callouts 1 through 10):
- Someone (for example, a project manager or lead developer) collects initial requirements and turns them into tasks.
- Developers use Microsoft Visual Studio Team Foundation Server 2010 or other tools to track the development progress and store custom source code.
- Because source code is stored in a centralized location, you can create automated builds for integration and unit testing purposes. You can also automate testing activities to increase the overall quality of the customizations.
- After custom solutions have successfully gone through acceptance testing, your development team can continue to the pre-production or quality assurance environment.
- The pre-production environment should resemble the production environment as much as possible. This often means that the pre-production environment has the same patch level and configurations as the production environment. The purpose of this environment is to ensure that your custom solutions will work in production.
- Occasionally, copy the production database to the pre-production environment, so that you can imitate the upgrade actions that will be performed in the production environment.
- After the customizations are verified in the pre-production environment, they are deployed either directly to production or to a production staging environment and then to production.
- After the customizations are deployed to production, they run against the production database.
- End users work in the production environment, and give feedback and ideas concerning the different functionalities. Issues and bugs are reported and tracked through established reporting and tracking processes.
- Feedback, bugs, and other issues in the production environment are turned into requirements, which are prioritized and turned into developer tasks. Figure 2 shows how multiple developer teams can work with and process bug reports and change requests that are received from end users of the production environment. The model in Figure 2 also shows how development teams might coordinate their solution packages. For example, the framework team and the functionality development team might follow separate versioning models that must be coordinated as they track bugs and changes.
Figure 2. Change management involving multiple developer teams

Integrating Testing and Build Verification Environments into a SharePoint 2010 ALM Process
In larger projects, quality assurance (QA) personnel might use an additional build verification or user acceptance testing (UAT) farm to test and verify the builds in an environment that more closely resembles the production environment.
Typically, a build verification farm has multiple servers to ensure that custom solutions are deployed correctly. Figure 3 shows a potential model for relating development integration and testing environments, build verification farms, and production environments. In this particular model, the pre-production or QA farm and the production farm switch places after each release. This model minimizes any downtime that is related to maintaining the environments.

Integrating SharePoint Designer 2010 into a SharePoint 2010 ALM Process
Another significant consideration in your ALM model is Microsoft SharePoint Designer 2010. SharePoint 2010 is an excellent platform for no-code solutions, which can be created and then deployed directly to the production environment by using SharePoint Designer 2010. These customizations are stored in the content database and are not stored in your source code repository.
General designer activities and how they interact with development activities are another consideration. Will you be creating page layouts directly within your production environment, or will you deploy them as part of your packaged solutions? There are advantages and disadvantages to both options.
Your specific ALM model depends completely on the custom solutions and the customizations that you plan to make, and on your own policies. Your ALM process does not have to be as complex as the one described in this section. However, you must establish a firm ALM model early in the process as you plan and create your development environment and before you start creating your custom solutions.
Next, we discuss specific tools and capabilities that are related to SharePoint 2010 development that you can use when considering how to create a model for SharePoint ALM that will work best for your development team.
One major advantage of the SharePoint 2010 development platform is that it provides the ability to save sites as solution packages. A solution package is a deployable, reusable package stored in a CAB file with a .wsp extension. You can create a solution package either by using the SharePoint 2010 user interface (UI) in the browser, SharePoint Designer 2010, or Microsoft Visual Studio 2010. In the browser and SharePoint Designer 2010 UIs, solution packages are also called templates. This flexibility enables you to create and design site structures in a browser or in SharePoint Designer 2010, and then import these customizations into Visual Studio 2010 for more development. Figure 4 shows this process.

When the customizations are completed, you can deploy your solution package to SharePoint for use. After modifying the existing site structure by using a browser, you can start the cycle again by saving the updated site as a solution package.
This interaction among the tools also enables you to use other tools. For example, you can design a workflow process in Microsoft Visio 2010 and then import it to SharePoint Designer 2010 and from there to Visual Studio 2010. For instructions on how to design and import a workflow process, see Create, Import, and Export SharePoint Workflows in Visio.
For more information about creating solution packages in SharePoint Designer 2010, see Save a SharePoint Site as a Template. For more information about creating solution packages in Visual Studio 2010, see Creating SharePoint Solution Packages.
SharePoint Designer 2010 differs from Microsoft Office SharePoint Designer 2007 in that its orientation has shifted from the page to features and functionality. The improved UI provides greater flexibility for creating and designing different functionalities. It provides rich tooling for building complete, reusable, and process-centric applications. For more information about the new capabilities and features of SharePoint Designer 2010, see Getting Started with SharePoint Designer.
You can also use SharePoint Designer 2010 to modify modular components developed with Visual Studio 2010. For example, you can create Web Parts and other controls in Visual Studio 2010, deploy them to a SharePoint farm, and then edit them in SharePoint Designer 2010.
The primary target users for SharePoint Designer 2010 are IT personnel and information workers who can use this application to create customizations in a production environment. For this reason, you must decide on an ALM model for your particular environment that defines which kinds of customizations will follow the complete ALM development process and which customizations can be done by using SharePoint Designer 2010. Developers are secondary target users. They can use SharePoint Designer 2010 as a part of their development activities, especially during initial creation of customization packages and also for rapid development and prototyping. Your ALM process must also define where and how to fit SharePoint Designer 2010 into the broader development model.
A key challenge of using SharePoint Designer 2010 is that when you use it to modify files, all of your changes are stored in the content database instead of in the file system. For example, if you customize a master page for a specific site by using SharePoint Designer 2010 and then design and deploy new branding elements inside a solution package, the changes are not available for the site that has the customized master page, because that site is using the version of the master page that is stored in the content database.
To minimize challenges such as these, SharePoint Designer 2010 contains new features that enable you to control usage of SharePoint Designer 2010 in a specific environment. You can apply these control settings at the web application level or site collection level. If you disable some action at the web application level, that setting cannot be changed at the site collection level.
SharePoint Designer 2010 makes the following settings available:
- Allow site to be opened in SharePoint Designer 2010.
- Allow customization of files.
- Allow customization of master pages and layout pages.
- Allow site collection administrators to see the site URL structure.
Because the primary purpose of SharePoint Designer 2010 is to customize content on an existing site, it does not support source code control. By default, pages that you customize by using SharePoint Designer 2010 are stored inside a versioned SharePoint library. This provides you with simple support for versioning, but not for full-featured source code control.
When you save a site as a solution package in the browser (from the Save as Template page in Site Settings), SharePoint 2010 stores the site as a solution package (.wsp) file and places it in the Solution Gallery of that site collection. You can then download the solution package from the Solution Gallery and import it into Visual Studio 2010 by using the Import SharePoint Solution Package template, as shown in Figure 5.

SharePoint 2010 solution packages contain many improvements that take advantage of new capabilities that are available in its feature framework. The following list contains some of the new feature elements that can help you manage your development projects and upgrades.
- SourceVersion for WebFeature and SiteFeature
- WebTemplate feature element
- PropertyBag feature element
- $ListId:Lists
- WorkflowAssociation feature element
- CustomSchema attribute on ListInstance
- Solution dependencies
After you import your project, you can start customizing it any way you like.
 Note Note |
|---|
| Because this capability is based on the WebTemplate feature element, which is based on a corresponding site definition, the resulting solution package will contain definitions for everything within the site. For more information about creating and using web templates, see Web Templates. |
Visual Studio 2010 supports source code control (as shown in Figure 6), so that you can store the source code for your customizations in a safer and more secure central location, and enable easy sharing of customizations among developers.

The specific way in which your developers access this source code and interact with each other depends on the structure of your team development environment. The next section of this article discusses key concerns and considerations that you should consider when you build a team development environment for SharePoint 2010.
As in any ALM planning process, your SharePoint 2010 planning should include the following steps:
- Identify and create a process for initiating projects.
- Identify and implement a versioning system for your source code and other deployed resources.
- Plan and implement version control policies.
- Identify and create a process for work item and defect tracking and reporting.
- Write documentation for your requirements and plans.
- Identify and create a process for automated builds and continuous integration.
- Standardize your development model for repeatability.
Microsoft Visual Studio Team Foundation Server 2010 (shown in Figure 7) provides a good potential platform for many of these elements of your ALM model.

When you have established your model for team development, you must choose either a collection of tools or Microsoft Visual Studio Team Foundation Server 2010 to manage your development. Microsoft Visual Studio Team Foundation Server 2010 provides direct integration into Visual Studio 2010, and it can be used to manage your development process efficiently. It provides many capabilities, but how you use it will depend on your projects.
You can use the Microsoft Visual Studio Team Foundation Server 2010 for the following activities:
- Tracking work items and reporting the progress of your development. Microsoft Visual Studio Team Foundation Server 2010 provides tools to create and modify work items that are delivered not only from Visual Studio 2010, but also from the Visual Studio 2010 web client.
- Storing all source code for your custom solutions.
- Logging bugs and defects.
- Creating, executing, and managing your testing with comprehensive testing capabilities.
- Enabling continuous integration of your code by using the automated build capabilities.
Microsoft Visual Studio Team Foundation Server 2010 also provides a basic installation option that installs all required functionalities for source control and automated builds. These are typically the most used capabilities of Microsoft Visual Studio Team Foundation Server 2010, and this option helps you set up your development environment more easily.
SharePoint 2010 must be installed on a development computer to take full advantage of its development capabilities. If you are developing only remote applications, such as solutions that use SharePoint web services, the client object model, or REST, you could potentially develop solutions on a computer where SharePoint 2010 is not installed. However, even in this case, your developers’ productivity would suffer, because they would not be able to take advantage of the full debugging experience that comes with having SharePoint 2010 installed directly on the development computer.
The design of your development environment depends on the size and needs of your development team. Your choice of operating system also has a significant impact on the overall design of your team development process. You have three main options for creating your development environments, as follows:
- You can run SharePoint 2010 directly on your computer’s client operating system. This option is available only when you use the 64-bit version of Windows 7, Windows Vista Service Pack 1, or Windows Vista Service Pack 2.
- You can use the boot to Virtual Hard Drive (VHD) option, which means that you start your laptop by using the operating system in VHD. This option is available only when you use Windows 7 as your primary operating system.
- You can use virtualization capabilities. If you choose this option, you have a choice of many options. But from an operational viewpoint, the option that is most likely the easiest to implement is a centralized virtualized environment that hosts each developer’s individual development environment.
The following sections take a closer look at these three options.
SharePoint 2010 on a Client Operating System
If you are using the 64-bit version of Windows 7, Windows Vista Service Pack 1, or Windows Vista Service Pack 2, you can install SharePoint Foundation 2010 or SharePoint Server 2010. For more information about installing SharePoint 2010 on supported operating systems, see Setting Up the Development Environment for SharePoint 2010 on Windows Vista, Windows 7, and Windows Server 2008.
Figure 8 shows how a computer that is running a client operating system would operate within a team development environment.

A benefit of this approach is that you can take full advantage of any of your existing hardware that is running one of the targeted client operating systems. You can also take advantage of pre-existing configurations, domains, and enterprise resources that your enterprise supports. This could mean that you would require little or no additional IT support. Your developers would also face no delays (such as booting up a virtual machine or connecting to an environment remotely) in accessing their development environments.
However, if you take this approach, you must ensure that your developers have access to sufficient hardware resources. In any development environment, you should use a computer that has an x64-capable CPU, and at least 2 gigabytes (GB) of RAM to install and run SharePoint Foundation 2010; 4 GB of RAM is preferable for good performance. You should use a computer that has 6 GB to 8 GB of RAM to install and run SharePoint Server 2010.
A disadvantage of this approach is that your environments will not be centrally managed, and it will be difficult to keep all of your project-dependent environmental requirements in sync. It might also be advisable to write batch files that start and stop some of the SharePoint-related services so that when your developers are not working with SharePoint 2010, these services will not consume resources and degrade the performance of their computers.
The lack of centralized maintenance could hurt developer productivity in other ways. For example, this might be an unwieldy approach if your team is working on a large Microsoft SharePoint Online project that is developing custom solutions for multiple services (for example, the equivalents of http://intranet, http://mysite, http://teams, http://secure, http://search, http://partners, and http://www.internet.com) and deploying these solutions in multiple countries or regions.
If you are developing on a computer that is running a client operating system in a corporate domain, each development computer would have its own name (and each local domain name would be different, such as http://dev 1 or http://dev2). If each developer is implementing custom functionalities for multiple services, you must use different port numbers to differentiate each service (for example, http://dev1 for http://intranet and http://dev1:81 for http://mysite). If all of your developers are using the same Visual Studio 2010 projects, the project debugging URL must be changed manually whenever a developer takes the latest version of a project from your source code repository.
This would create a manual step that could hurt developer productivity, and it would also diminish the efficiency of any scripts that you have written for setting up development environments, because the individual environments are not standardized. Some form of centralization with virtualization is preferable for large enterprise development projects.
SharePoint 2010 on Windows 7 and Booting to Virtual Hard Drive
If you are using Windows 7, you can also create a VHD out of an existing Windows Server 2008 image on which SharePoint 2010 is installed in Windows Hyper-V, and then configure Windows 7 with BDCEdit.exe so that it boots directly to the operating system on the VHD. To learn more about this kind of configuration, see Deploy Windows on a Virtual Hard Disk with Native Boot and Boot from VHD in Win 7.
Figure 9 shows how a computer that is running Windows 7 and booting to VHD would operate within a team development environment.

An advantage of this approach is the flexibility of having multiple dedicated environments for an individual project, enabling you to isolate each development environment. Your developers will not accidentally cross-reference any artifacts within their projects, and they can create project-dependent environments.
However, this option has considerable hardware requirements, because you are using the available hardware and resources directly on your computers.
SharePoint 2010 in Centralized Virtualized Environments
In a centralized virtualized environment, you host your development environments in one centralized location, and developers access these environments through remote connections. This means that you use Windows Hyper-V in the centralized location and copy a VHD for every developer as needed. Each VHD is configured to be available from the corporate network, so that when it starts, it can be accessed by using remote connections.
Figure 10 shows how a centralized virtualized team development environment would operate.

An advantage of this approach is that the hardware requirements for individual developer computers are relatively few because the actual work happens in a centralized environment. Developers could even use computers with 1 GB of RAM as their clients and then connect remotely to the centralized location. You can also manage environments easily from one centralized location, making adjustments to them whenever necessary.
Your centralized host will have significantly high hardware requirements, but developers can easily start and stop these environments. This enables you to use the hardware that you have allocated for your development environments more efficiently. Additionally, this approach provides a ready platform for more extensive testing environments for your custom code (such as multi-server farms).
After you set up your team development environment, you can start taking advantage of the deployment and upgrade capabilities that are included with the new solution packaging model in SharePoint 2010. The following sections describe how to take advantage of these new capabilities in your ALM model.
The SharePoint 2010 solution packaging model provides many useful features that will help you plan for deploying custom solutions and managing the upgrade process. You can implement assembly versioning by applying binding redirects in your web application configuration file. You can also apply versioning to your feature upgrades, and feature upgrade actions enable you to manage changes that will be necessary on your existing sites to accommodate feature upgrades. These upgrade actions can be handled declaratively or programmatically.
The feature upgrade query object model enables you to create queries in your code that look for features on your existing sites that can be upgraded. You can use this object model to obtain relevant information about all of the features and feature versions that are deployed on your SharePoint 2010 sites. In your solution manifest file, you can also configure the type of Internet Information Services (IIS) recycling to perform during a solution upgrade.
The following sections go into greater details about these capabilities and how you can use them.
Using Assembly BindingRedirect with SharePoint 2010 Assemblies
The BindingRedirect feature element can be added to your web applications configuration file. It enables you to redirect from earlier versions of installed assemblies to newer versions. Figure 11 shows how the XML configuration from the solution manifest file instructs SharePoint to add binding redirection rules to the web application configuration file. These rules forward any reference to version 1.0 of the assembly to version 2.0. This is required in your solution manifest file if you are upgrading a custom solution that uses assembly versioning and if there are existing instances of the solution and the assembly on your sites.

It is a best practice to use assembly versioning, because it gives you an easy way to track the versions of a solution that are deployed to your production environments.
SharePoint 2010 Feature Versioning
The support for feature versioning in SharePoint 2010 provides many capabilities that you can use when you are upgrading features. For example, you can use the SPFeature.Version property to determine which versions of a feature are deployed on your farm, and therefore which features must be upgraded. For a code sample that demonstrates how to do this, see Version.
Feature versioning in SharePoint 2010 also enables you to define a value for the SPFeatureDependency.MinimumVersion property to handle feature dependencies. For example, you can use the MinimumVersion property to ensure that a particular version of a dependent feature is activated. Feature dependencies can be added or removed in each new version of a feature.
The SharePoint 2010 feature framework has also enhanced the object model level to support feature versioning more easily. You can use the QueryFeatures method to retrieve a list of features, and you can specify both feature version and whether a feature requires an upgrade. The QueryFeatures method returns an instance of SPFeatureQueryResultCollection, which you can use to access all of the features that must be updated. This method is available from multiple scopes, because it is available from the SPWebService, SPWebApplication, SPContentDatabase, and SPSite classes. For more information about this overloaded method, see QueryFeatures(), QueryFeatures(), QueryFeatures(), and QueryFeatures(). For an overview of the feature upgrade object model, see Feature Upgrade Object Model.
The following section summarizes many of the new upgrade actions that you can apply when you are upgrading from one version of a feature to another.
SharePoint 2010 Feature Upgrade Actions
Upgrade actions are defined in the Feature.xml file. The SPFeatureReceiver class contains a FeatureUpgrading method, which you can use to define actions to perform during an upgrade. This method is called during feature upgrade when the feature’s Feature.xml file contains one or more <CustomUpgradeAction> tags, as shown in the following example.
<UpgradeActions>
<CustomUpgradeAction Name="text">
...
</CustomUpgradeAction>
</UpgradeActions>
Each custom upgrade action has a name, which can be used to differentiate the code that must be executed in the feature receiver. As shown in following example, you can parameterize custom action instances.
<Feature xmlns="http://schemas.microsoft.com/sharepoint/">
<UpgradeActions>
<VersionRange EndVersion ="2.0.0.0">
<!-- First action-->
<CustomUpgradeAction Name="example">
<Parameters>
<Parameter Name="parameter1">Whatever</Parameter>
<Parameter Name="anotherparameter">Something meaningful</Parameter>
<Parameter Name="thirdparameter">additional configurations</Parameter>
</Parameters>
</CustomUpgradeAction>
<!-- Second action-->
<CustomUpgradeAction Name="SecondAction">
<Parameters>
<Parameter Name="SomeParameter1">Value</Parameter>
<Parameter Name="SomeParameter2">Value2</Parameter>
<Parameter Name="SomeParameter3">Value3</Parameter>
</Parameters>
</CustomUpgradeAction>
</VersionRange>
</UpgradeActions>
</Feature>
This example contains two CustomUpgradeAction elements, one named example and the other named SecondAction. Both elements have different parameters, which are dependent on the code that you wrote for the FeatureUpgrading event receiver. The following example shows how you can use these upgrade actions and their parameters in your code.
<summary>
Called when feature instance is upgraded for each of the custom upgrade actions in the Feature.xml file.
</summary>
<param name="properties">Feature receiver properties</param>
<param name="upgradeActionName">Upgrade action name</param>
<param name="parameters">Custom upgrade action parameters</param>
public override FeatureUpgrading(SPFeatureReceiverProperties properties,
string upgradeActionName,
System.Collections.Generic.IDictionary<string, string> parameters)
{
// Do not do anything, if feature scope is not correct.
(properties.Feature.Parent SPWeb)
{
// Log that feature scope is incorrect.
return;
}
switch (upgradeActionName)
{
"example":
FeatureUpgradeManager.UpgradeAction1(parameters["parameter1"], parameters["AnotherParameter"],
parameters["ThirdParameter"]);
break;
"SecondAction":
FeatureUpgradeManager.UpgradeAction1(parameters["SomeParameter1"], parameters["SomeParameter2"],
parameters["SomeParameter3"]);
break;
default:
// Log that code for action does not exist.
break;
}
}
You can have as many upgrade actions as you want, and you can apply them to version ranges. The following example shows how you can apply upgrade actions to version ranges of a feature.
<Feature xmlns="http://schemas.microsoft.com/sharepoint/">
<UpgradeActions>
<VersionRange BeginVersion="1.0.0.0" EndVersion ="2.0.0.0">
...
</VersionRange>
<VersionRange BeginVersion="2.0.0.1" EndVersion="3.0.0.0">
...
</VersionRange>
<VersionRange BeginVersion="3.0.0.1" EndVersion="4.0.0.0">
...
</VersionRange>
</UpgradeActions>
</Feature>
The AddContentTypeField upgrade action can be used to define additional fields for an existing content type. It also provides the option of pushing these changes down to child instances, which is often the preferred behavior. When you initially deploy a content type to a site collection, a definition for it is created at the site collection level. If that content type is used in any subsite or list, a child instance of the content type is created. To ensure that every instance of the specific content type is updated, you must set the PushDown attribute to , as shown in the following example.
<Feature xmlns="http://schemas.microsoft.com/sharepoint/">
<UpgradeActions>
<VersionRange EndVersion ="2.0.0.0">
<AddContentTypeField ContentTypeId="0x0101002b0e208ace0a4b7e83e706b19f32cab9"
FieldId="{ccbcd479-94c9-4f3a-95c4-58897da434fe}"
PushDown="True"/>
</VersionRange>
</UpgradeActions>
</Feature>
For more information about working with content types programmatically, see Introduction to Content Types.
The ApplyElementManifests upgrade action can be used to apply new artifacts to a SharePoint 2010 site without reactivating features. Just as you can add new elements to any new SharePoint elements.xml file, you can instruct SharePoint to apply content from a specific elements file to sites where a given feature is activated.
You can use this upgrade action if you are upgrading an existing feature whose FeatureActivating event receiver performs actions that you do not want to execute again on sites where the feature is deployed. The following example demonstrates how to include this upgrade action in a Feature.xml file.
<Feature xmlns="http://schemas.microsoft.com/sharepoint/">
<UpgradeActions>
<VersionRange EndVersion ="2.0.0.0">
<ApplyElementManifests>
<ElementManifest Location="AdditionalV2Fields\Elements.xml"/>
</ApplyElementManifests>
</VersionRange>
</UpgradeActions>
</Feature>
An example of a use case for this upgrade action involves adding new .webpart files to a feature in a site collection. You can use the ApplyElementManifest upgrade action to add those files without reactivating the feature. Another example would involve page layouts, which contain initial Web Part instances that are defined in the file element structure of the feature element file. If you reactivate this feature, you will get duplicates of these Web Parts on each of the page layouts. In this case, you can use the ElementManifest element of the ApplyElementManifests upgrade action to add new page layouts to a site collection that uses the feature without reactivating the feature.
The MapFile element enables you to map a URL request to an alternative URL. The following example demonstrates how to include this upgrade action in a Feature.xml file.
<Feature xmlns="http://schemas.microsoft.com/sharepoint/">
<UpgradeActions>
<MapFile FromPath="Features\MapPathDemo_MapPathDemo\PageDeployment\MyExamplePage.aspx"
ToPath="Features\MapPathDemo_MapPathDemo\PageDeployment\MyExamplePage2.aspx" />
</UpgradeActions>
</Feature>
Mapping URLs in this way would be useful to you in a case where you have to deploy a new version of a page that was customized by using SharePoint Designer 2010. The resulting customized page would be served from the content database. When you deploy the new version of the page, the new version will not appear because content for that page is coming from the database and not from the file system. You could work around this problem by using the MapFile element to redirect requests for the old version of the page to the newer version.
It is important to understand that the FeatureUpgrading method is called for each feature instance that will be updated. If you have 10 sites in your site collection and you update a web-scoped feature, the feature receiver will be called 10 times for each site context. For more information about how to use these new declarative feature elements, see Feature.xml Changes.
Upgrading SharePoint 2010 Features: A High-Level Walkthrough
This section describes at a high level how you can put these feature-versioning and upgrading capabilities to work. When you create a new version of a feature that is already deployed on a large SharePoint 2010 farm, you must consider two different scenarios: what happens when the feature is activated on a new site and what happens on sites where the feature already exists. When you add new content to the feature, you must first update all of the existing definitions and include instructions for upgrading the feature where it is already deployed.
For example, perhaps you have developed a content type to which you must add a custom site column named City. You do this in the following way:
- Add a new element file to the feature. This element file defines the new site column and modifies the Feature.xml file to include the element file.
- Update the existing definition of the content type in the existing feature element file. This update will apply to all sites where the feature is newly deployed and activated.
- Define the required upgrade actions for the existing sites. In this case, you must ensure that the newly added element file for the additional site column is deployed and that the new site column is associated with the existing content types. To achieve these two objectives, you add the ApplyElementManifests and the AddContentTypeField upgrade actions to your Feature.xml file.
When you deploy the new version of the feature to existing sites and upgrade it, the upgrade actions are applied to sites one by one. If you have defined custom upgrade actions, the FeatureUpgrading method will be called as many times as there are instances of the feature activated in your site collection or farm.
Figure 12 shows how the different components of this scenario work together when you perform the upgrade.

Different sites might have different versions of a feature deployed on them. In this case, you can create version ranges, which define specific actions to perform when you are upgrading from one version to another. If a version range is not defined, all upgrade actions will be applied during each upgrade.
Figure 13 shows how different upgrade actions can be applied to version ranges.

In this example, if a given site is upgrading directly from version 1.0 to version 3.0, all configurations will be applied because you have defined specific actions for upgrading from version 1.0 to version 2.0 and from 2.0 to version 3.0. You have also defined actions that will be applied regardless of feature version.
Code Design Guidelines for Upgrading SharePoint 2010 Features
To provide more flexibility for your code, you should not place your upgrade code directly inside the FeatureUpgrading event receiver. Instead, put the code in some centralized location and refer to it inside the event receiver, as shown in Figure 14.

By placing your upgrade code inside a centralized utility class, you increase both the reusability and the testability of your code, because you can perform the same actions in multiple locations. You should also try to design your custom upgrade actions as generically as possible, using parameters to make them applicable to specific upgrade scenarios.
Solution Lifecycles: Upgrading SharePoint 2010 Solutions
If you are upgrading a farm (full-trust) solution, you must first deploy the new version of your solution package to a farm.
Execute either of the following scripts from a command prompt to deploy updates to a SharePoint farm. The first example uses the Stsadm.exe command-line tool.
stsadm -o upgradesolution -name solution.wsp -filename solution.wsp
The second example uses the Update-SPSolution Windows PowerShell cmdlet.
UpdateSPSolution Identity contoso_solution.wsp LiteralPath c:\contoso_solution_v2.wsp GACDeployment
After the new version is deployed, you can perform the actual upgrade, which executes the upgrade actions that you defined in your Feature.xml files.
A farm solution upgrade can be performed either farm-wide or at a more granular level by using the object model. A farm-wide upgrade is performed by using the Psconfig command-line tool, as shown in the following example.
psconfig -cmd upgrade -inplace b2b
| Note |
|---|
| This tool causes a service break on the existing sites. During the upgrade, all feature instances throughout the farm for which newer versions are available will be upgraded. |
You can also perform upgrades for individual features at the site level by using the Upgrade method of the SPFeature class. This method causes no service break on your farm, but you are responsible for managing the version upgrade from your code. For a code example that demonstrates how to use this method, see SPFeature.Upgrade.
Upgrading a sandboxed solution at the site collection level is much more straightforward. Just upload the SharePoint solution package (.wsp file) that contains the upgraded features. If you have a previous version of a sandboxed solution in your solution gallery and you upload a newer version, an Upgrade option appears in the UI, as shown in Figure 15.

After you select the Upgrade option and the upgrade starts, all features in the sandboxed solution are upgraded.
This article has discussed some considerations and examples of Application Lifecycle Management (ALM) design that are specific to SharePoint 2010, and it has also enumerated and described the most important capabilities and tools that you can integrate into the ALM processes that you choose to establish in your enterprise. The SharePoint 2010 feature framework and solution packaging model provide flexibility and power that you can put to work in your ALM processes.

![uml+activity+diagram+library+mgmt+book+return[1]](https://sharepointsamurai.files.wordpress.com/2014/06/umlactivitydiagramlibrarymgmtbookreturn1.jpg "activity diagram")


![ImageGen[1]](https://sharepointsamurai.files.wordpress.com/2014/06/imagegen1.png)
![image_thumb%25255B3%25255D[1]](https://sharepointsamurai.files.wordpress.com/2014/06/image_thumb25255b325255d1.png)
 +
+ ![microsoft_crm_wallpaper_02[1]](https://sharepointsamurai.files.wordpress.com/2014/06/microsoft_crm_wallpaper_021.jpg?w=167&h=125)








![clip_image001[6]](http://blogs.technet.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-00-46-82-metablogapi/1072.clip_5F00_image0016_5F00_7FA6F1CB.jpg "clip_image001[6]")






 One of the core concepts of Business Connectivity Services (BCS) for
One of the core concepts of Business Connectivity Services (BCS) for 































![PrimForWindowsRuntime[1]](https://sharepointsamurai.files.wordpress.com/2014/05/primforwindowsruntime1.png?w=474&h=307)

























![2008040211105590dad[1]](https://sharepointsamurai.files.wordpress.com/2014/04/2008040211105590dad1.gif)



![Outlook.com_[1]](https://sharepointsamurai.files.wordpress.com/2014/04/outlook-com_1.jpg)















![4336.SP2013SearchArchitecture[1]](https://sharepointsamurai.files.wordpress.com/2014/03/4336-sp2013searcharchitecture1.png)


















 Important
Important













 Figure 1. Select SAP in the Attach Data Source Wizard
Figure 1. Select SAP in the Attach Data Source Wizard Figure 2. Enter connection information in the Attach Data Source Wizard
Figure 2. Enter connection information in the Attach Data Source Wizard Figure 3. Select the BusinessPartner and Product entities in the Attach Data Source Wizard
Figure 3. Select the BusinessPartner and Product entities in the Attach Data Source Wizard Figure 4. Entity Designer showing the Product entity
Figure 4. Entity Designer showing the Product entity
 Figure 5. Properties on the BusinessPartner entity have been set to the appropriate business type
Figure 5. Properties on the BusinessPartner entity have been set to the appropriate business type Figure 6. The ProductDetail entity
Figure 6. The ProductDetail entity Figure 7. Adding a relationship
Figure 7. Adding a relationship Figure 8. Configuring the relationship
Figure 8. Configuring the relationship Figure 9. Adding a new Common Screen Set
Figure 9. Adding a new Common Screen Set Figure 10. Writing “created” code on the AddEditProduct screen
Figure 10. Writing “created” code on the AddEditProduct screen Figure 11. Control layout
Figure 11. Control layout Figure 12. Changing Product Pic Url to an Image control
Figure 12. Changing Product Pic Url to an Image control Figure 13. Properties of the Product Pic Url control
Figure 13. Properties of the Product Pic Url control Figure 14. The ViewProduct screen
Figure 14. The ViewProduct screen Figure 15. The AddEditProduct screen
Figure 15. The AddEditProduct screen











![SspId replacements file_thumb[2]](https://i0.wp.com/lh6.ggpht.com/-6rZRafRhLOM/UjjSPTBgdSI/AAAAAAAACgY/l_Ks0NtL3Sc/SspId%252520replacements%252520file_thumb%25255B2%25255D%25255B4%25255D.png "SspId replacements file_thumb[2]")


![Continuous Integration - Office 365 - custom VS configuration_thumb[2]](https://i0.wp.com/lh4.ggpht.com/-xxiJ42sc-jA/UjjSSmZBpzI/AAAAAAAACgw/PJqyQjzT0y4/Continuous%252520Integration%252520-%252520Office%252520365%252520-%252520custom%252520VS%252520configuration_thumb%25255B2%25255D%25255B4%25255D.png "Continuous Integration - Office 365 - custom VS configuration_thumb[2]")
![Continuous Integration - Office 365 - Managed Metadata solution_thumb[2]](https://i0.wp.com/lh4.ggpht.com/-hzeQXGVA8Q4/UjjSTged1BI/AAAAAAAACg4/ba5hhFZChTo/Continuous%252520Integration%252520-%252520Office%252520365%252520-%252520Managed%252520Metadata%252520solution_thumb%25255B2%25255D%25255B4%25255D.png "Continuous Integration - Office 365 - Managed Metadata solution_thumb[2]")
![Define custom configuration_thumb[2]](https://i0.wp.com/lh3.ggpht.com/-brGWrsxe8U0/UjjSVOVC5fI/AAAAAAAACg8/4XfGf9wRNqQ/Define%252520custom%252520configuration_thumb%25255B2%25255D%25255B4%25255D.png "Define custom configuration_thumb[2]")
![Define custom configuration 2_thumb[2]](https://i0.wp.com/lh3.ggpht.com/-hxfY2yShqmI/UjjSWJdyneI/AAAAAAAAChI/opDSsZuHm-c/Define%252520custom%252520configuration%2525202_thumb%25255B2%25255D%25255B4%25255D.png "Define custom configuration 2_thumb[2]")
![Define custom configuration 3_thumb[2]](https://i0.wp.com/lh5.ggpht.com/-rJFQe757Shw/UjjSXSrHFAI/AAAAAAAAChQ/3F9gAeGu8Ow/Define%252520custom%252520configuration%2525203_thumb%25255B2%25255D%25255B4%25255D.png "Define custom configuration 3_thumb[2]")















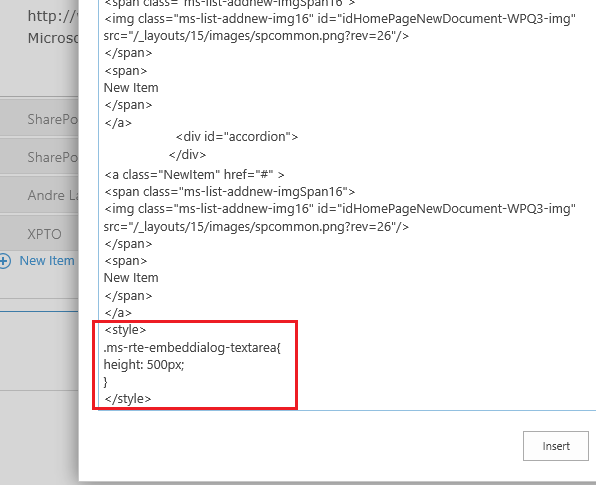





 Step 2:
Step 2: